#State of code search
Today, we're open-sourcing a set of coding evaluations, WebCode, that we built to evaluate web search for coding agents.
At Exa, we power search for most of the largest coding agent companies, and we have observed a surge in code search queries over the past year, with a particularly large jump at the end of 2025.
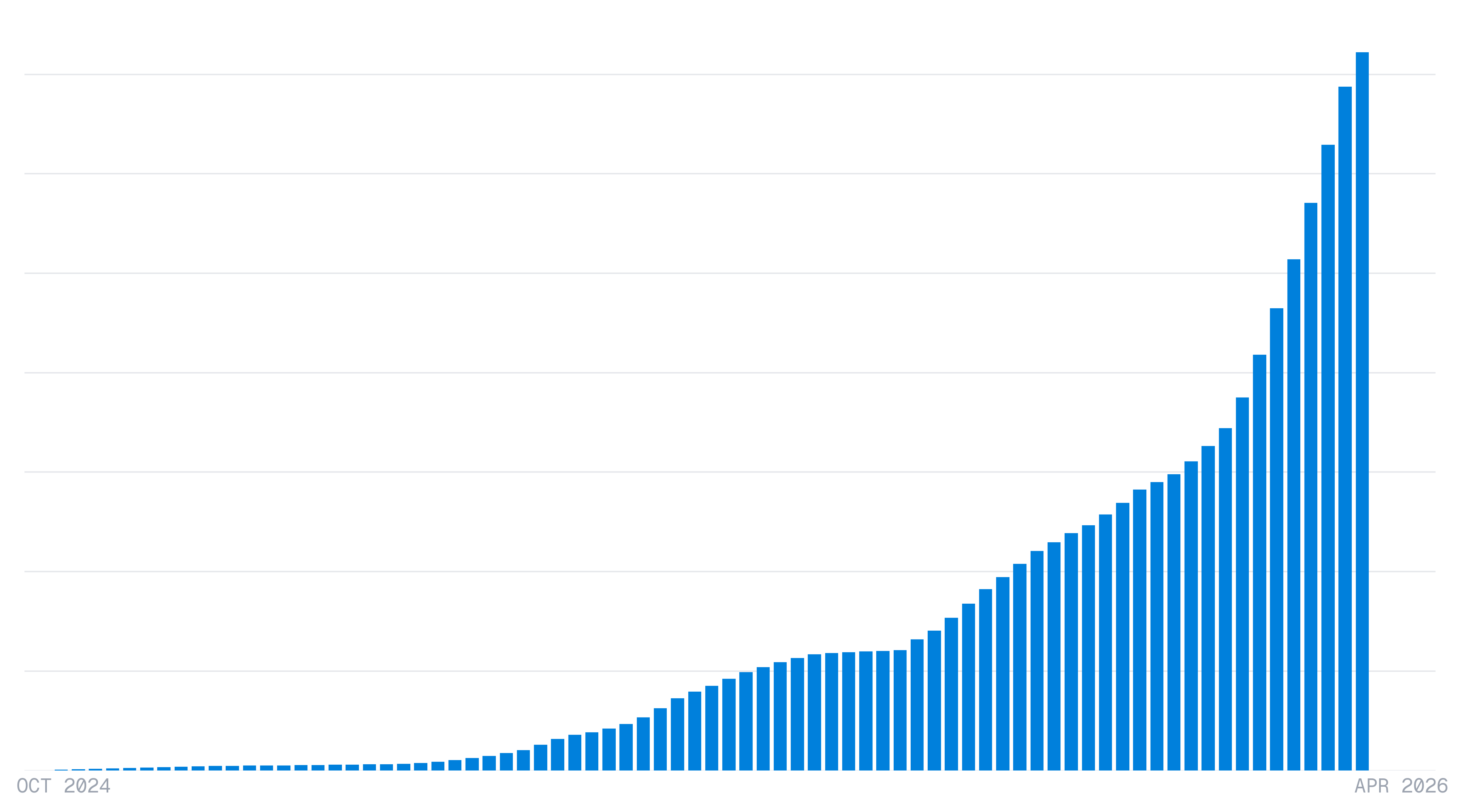
This growth pushed us to focus on code search, where precision is especially important: agents build on retrieved context across many steps, so stale or noisy search results can poison or even derail the reasoning processes of long-running agents. Documentation, changelogs, and issues update constantly, so we built a dedicated ingestion pipeline focused on fresh, clean results over full-page chrome.
To build better code search, effective methods for evaluating improvements are necessary. We observed that existing public web search benchmarks for coding agents have significant gaps.
#Why public benchmarks fail for retrieval
The canonical public benchmark problem of saturation, contamination, indirect training on eval problem sets is well-documented. OpenAI recently deprecated their own SWE-bench verified benchmark for exactly this reason1:
"Models that have seen the problems during training are more likely to succeed, because they have additional information needed to pass the underspecified tests... improvements on SWE-bench Verified no longer reflect meaningful improvements in models' real-world software development abilities."
A model with benchmark answers in its training distribution will produce correct outputs via parametric memory rather than through reasoning, and the eval has no mechanism to distinguish between the two.
Search is relevant precisely where this parametric memory fails: for tasks that are new, niche, or complex. For agents writing code, relevant documents such as changelogs, GitHub issues, and SDK docs are continuously updating, making real-time fluency a necessity.
#Evals Design
Search consists of two main components:
- Contents quality - contents that correctly answer the query
- Retrieval quality - identification of relevant URLs that contain the contents necessary to answer the query

#1. Contents Quality
#1.1 Evaluating against a golden extraction
Given a URL, we measure how faithfully each provider extracts its content, graded against a golden reference built from rendered screenshots and the DOM.
Defining "correct content" for a web page is a rabbit hole: should navigation be included? User-profile widgets? Sidebar links? We constrain the problem by asking: what content is maximally useful for an LLM answering a coding question from this page? That means keeping the substantive body - prose, code blocks, API signatures, tables - and stripping everything else.
To build the golden reference: we render each page in a Browserbase cloud browser, screenshot it end-to-end, and feed the screenshots alongside the DOM to a state-of-the-art multimodal model that produces markdown as faithful as possible to what's rendered. Working from rendered pixels rather than raw HTML means we see the page after JavaScript execution, lazy loading, and dynamic rendering - the same content a human would see in a browser.
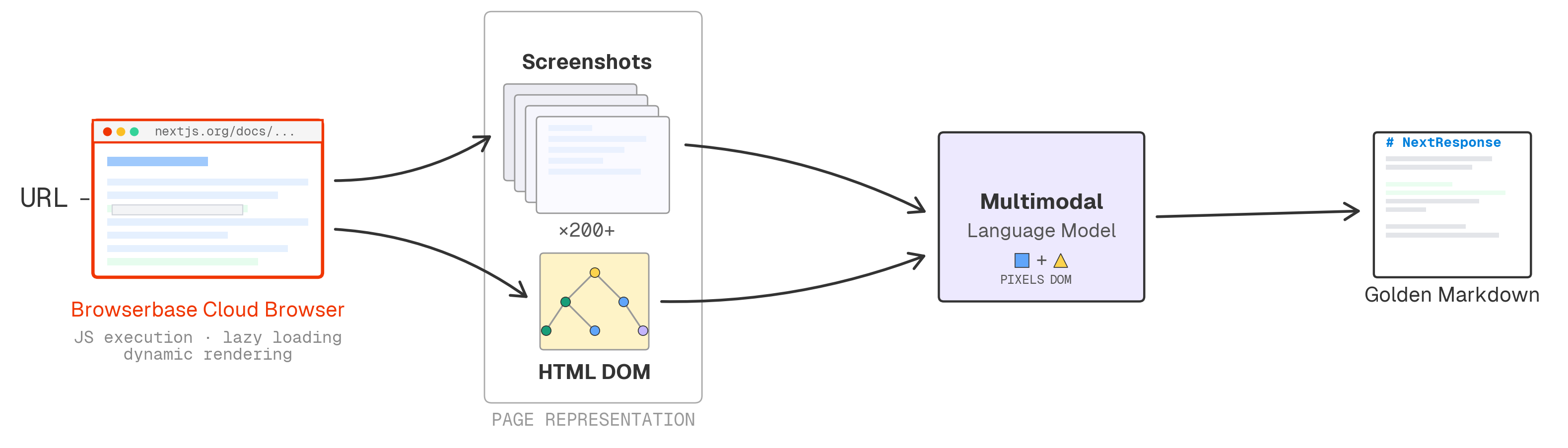
#How do we benchmark?
While the reference above is the ground truth every content extraction is scored against, there are nuances to scoring. An extractor can:
- fetch correctly but corrupt formatting
- preserve structure perfectly while dropping half the page
We score along multiple dimensions to diagnose where providers fail, using two complementary approaches:
- LLM-judged metrics that assess semantic dimensions string-matching struggles with: completeness (is the golden content present without excess?), accuracy (are numbers, code, and names faithful to the source?), and structure (are headings, lists, tables preserved?)
- Deterministic metrics from the NLP tradition for precise, reproducible measurement: signal (what fraction of the extraction is substantive content, derived from the ratio of golden to extracted length?), code and table recall (are code blocks and tables preserved?), and ROUGE-L (word-level longest common subsequence F1)
#Results
We evaluate our contents quality on a dataset of 250 URLs mined from simulated coding agent search distributions (Appendix A).
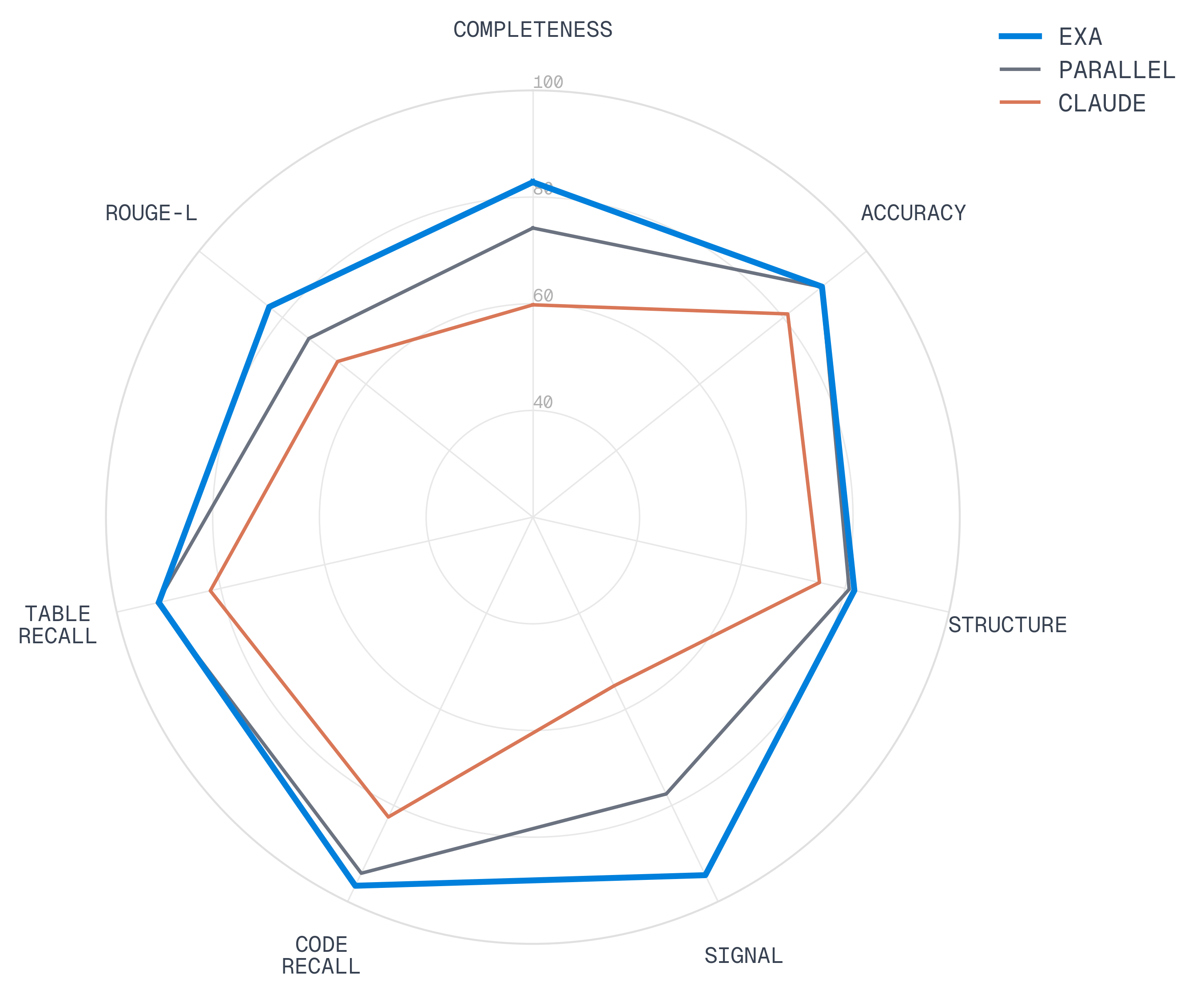
| Provider | Completeness | Signal | Structure | Accuracy | Code Recall | Table Recall | ROUGE-L |
|---|---|---|---|---|---|---|---|
| Exa | 82.8 | 94.5 | 81.8 | 89.3 | 96.7 | 91.9 | 83.2 |
| Parallel | 74.2 | 77.6 | 80.8 | 89.2 | 94.1 | 92.2 | 73.7 |
| Claude† | 59.8 | 55.1 | 75.1 | 81.1 | 82.4 | 82.0 | 66.8 |
*All scores 0-100. †Claude web_fetch_20260209 (allowed_callers=['direct']) returned empty content for 12.0% of URLs.
#Example: focused extraction vs full text
Extraction lengths vary by over an order of magnitude across providers for the same page. The 1x to 13x difference from the golden reference is driven by an excess consisting entirely of sidebars, navigation and chrome.
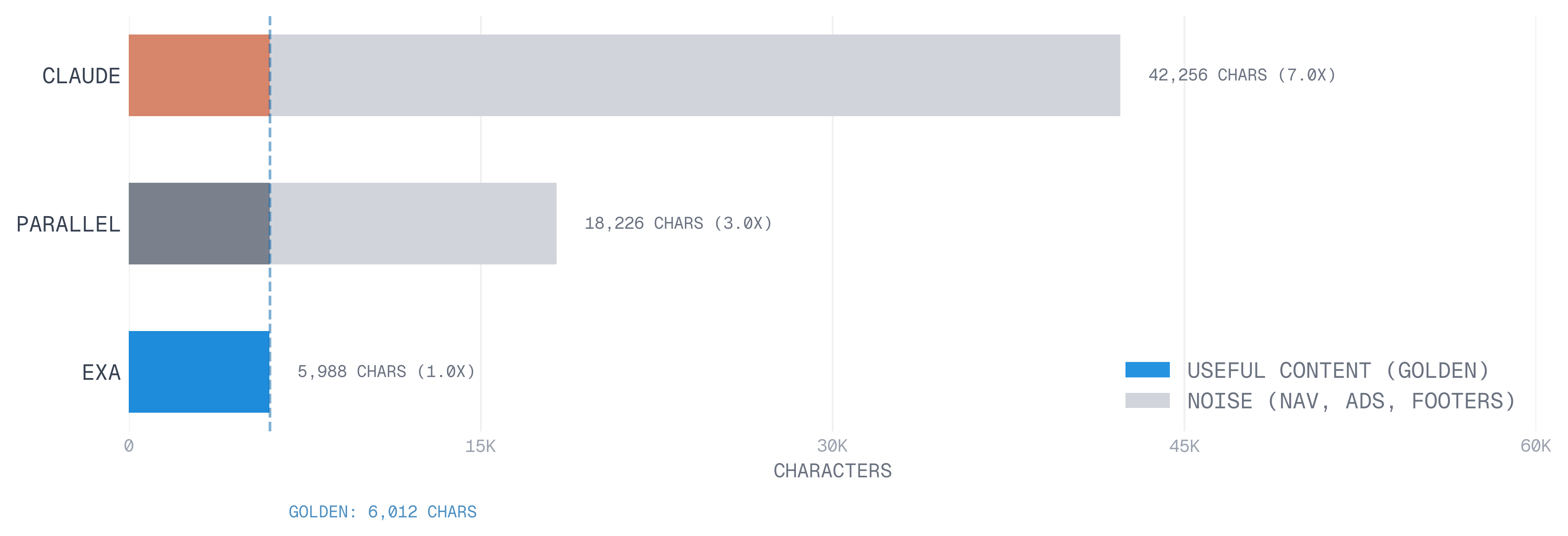
#1.2. Highlights: in-document search
The URL is still given, but now so is a query. Given this world-view, we measure whether providers can surface the relevant section (highlight) of the page that correctly answers the query. This can be viewed as the base case of RAG: instead of retrieving over the entire corpus, we instead retrieve over a single document.
To ensure token-efficient code search, measuring highlight (relevant section of the page) quality is important. However, we observed that the typical evaluation harness for RAG is prone to bidirectional failure modes:
- Highlights were incorrect but the synthesis LLM returned the correct answer
- Highlights were correct but the synthesis LLM returned the incorrect answer
The root cause: standard RAG evaluation is framed as a generative task: the synthesis LLM produces an answer, and that generation step is noisy enough to mask both good and bad extractions.
We reformulate it as a discriminative task. Instead of "generate the right answer from this context," we ask "does this context contain the right answer?" A frontier model can reliably discriminate whether a highlight contains a given fact, even when synthesis would be noisy. This gives us two independent axes:
- Correctness (generative): does the synthesized answer match the gold target? The judge never sees the highlights.
- Groundedness (discriminative): do the highlights contain the gold target answer? The judge never sees the synthesized answer.
#Example

Exa: extracted the relevant Apple documentation, including the exact bullet point that answers the question. The synthesis model cited it and produced a correct, grounded answer.
Claude: web_fetch_20260209 returned a JavaScript-required shell with no documentation content. Yet the synthesis model answered correctly anyway: it had memorized Apple's docs from training data. A correctness-only metric would score both identically.
#Results - importance of optimizing for groundedness
We evaluate each provider on the same dataset as the contents dataset.
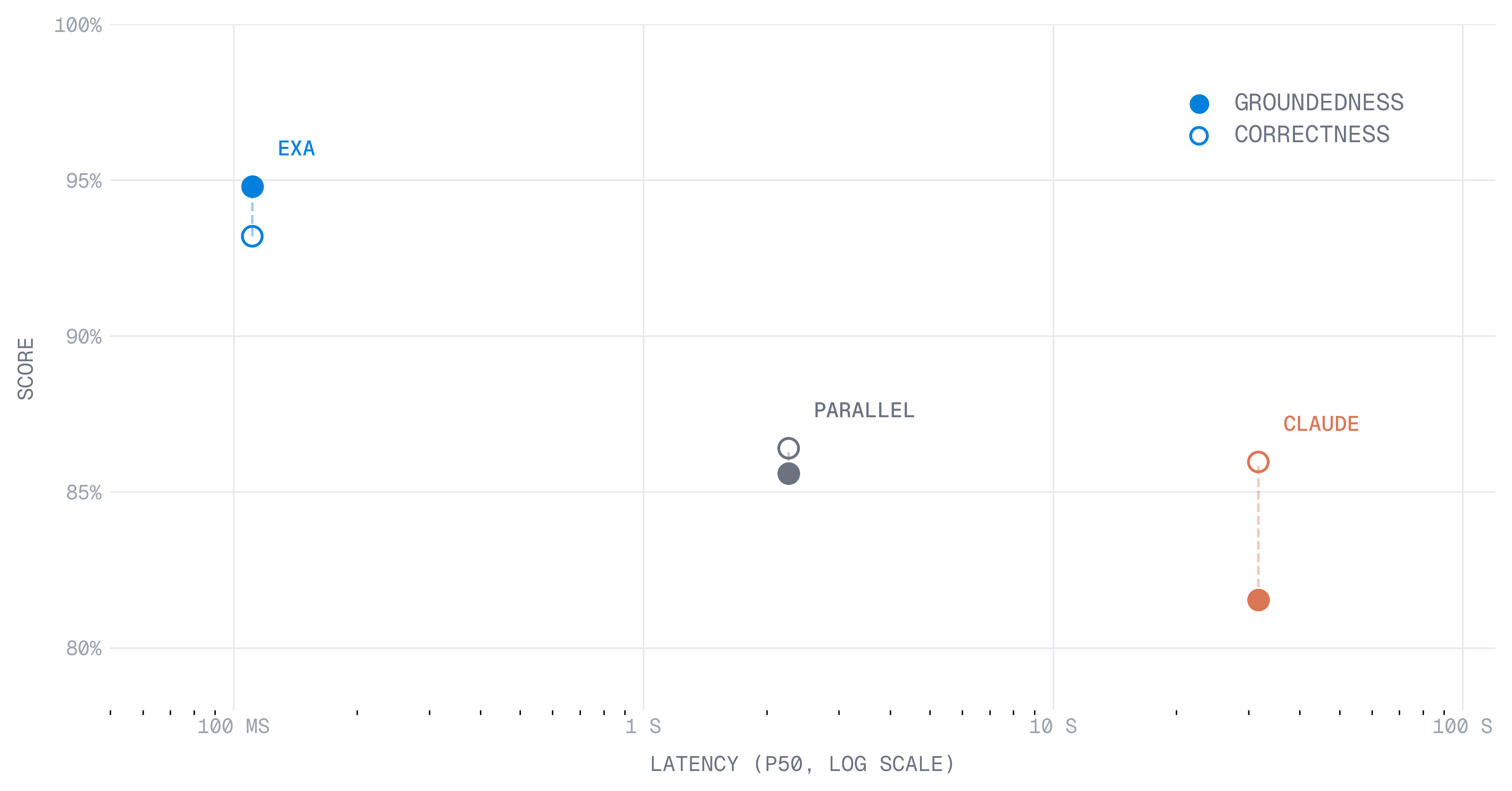
Correctness scores cluster around ~86%, while groundedness scores show much higher variance, better isolating capability differences across search providers. This suggests correctness primarily reflects the synthesis model, not the search provider.
#2. Retrieval Quality
#2.1. RAG: From a document to the entire web
In the prior section, we constrained our world view to a single document. Now, we expand our world view to the entire web and ask whether we are still able to retrieve the correct answer.
We generate question-answer pairs from long-context documentation pages: pages that run up to millions of characters. For each page, we select a niche segment buried deep in the document, construct a single factually verifiable question, and verify the answer using multiple research agents powered by Exa Deep. To further motivate each question from a retrieval perspective, we require that two frontier models fail to answer the question from parametric memory alone over three completions.
The final 317 queries (Appendix C) were dispatched to five providers (Exa, Brave, Perplexity, Parallel, and Tavily) and graded on groundedness: did the result set contain the correct answer? We also computed citation precision: not just whether the answer appeared, but what fraction of returned results actually contained it.
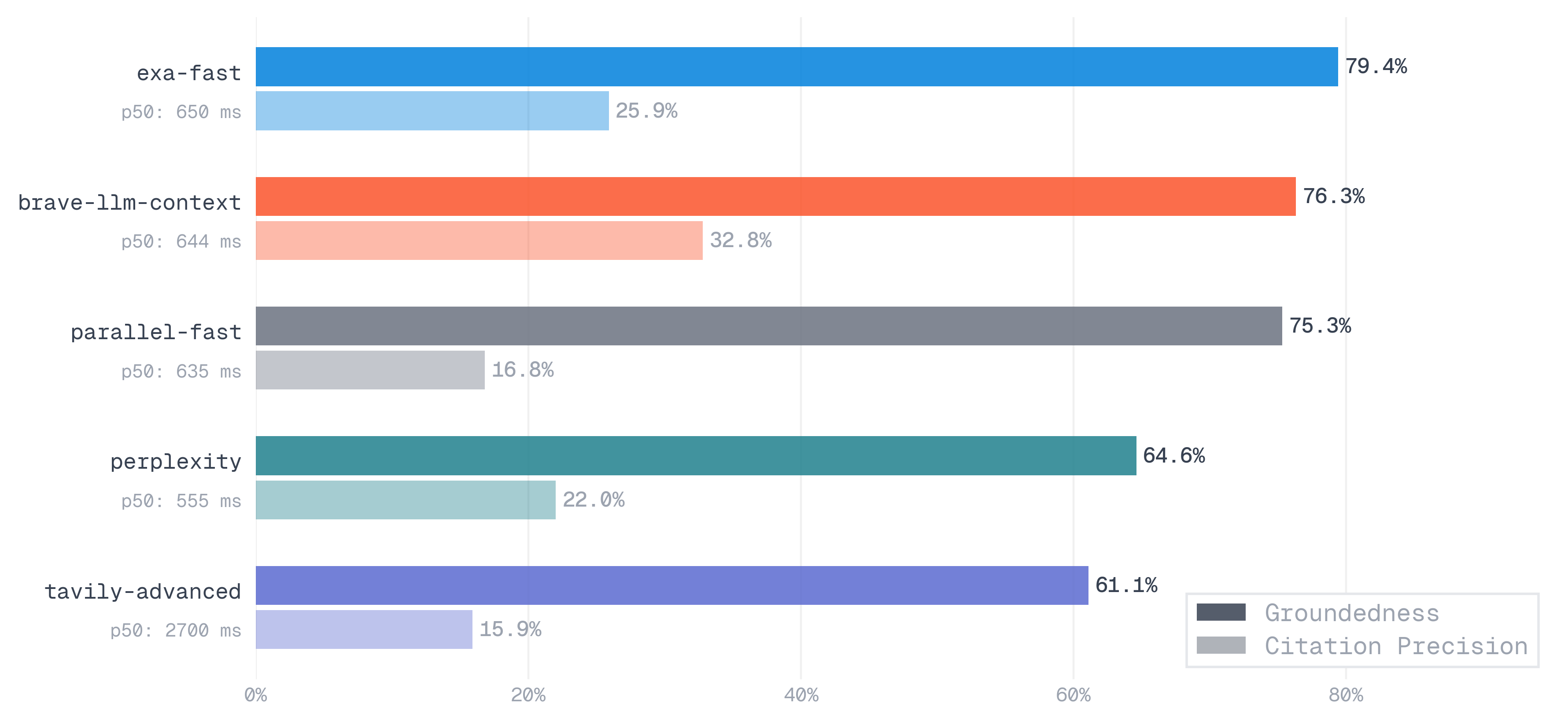
#2.2. End to End Coding Tasks
Finally, we evaluate retrieval quality in a sandboxed coding environment with bash tool calls and unit tests - closely mirroring real-world autonomous coding workflows.
Existing benchmarks such as TerminalBench focus primarily on reasoning and tool use, and generally do not require web search. In fact, we found no public benchmark that explicitly evaluates a coding agent's ability to use web search. Therefore, we built our own benchmark.
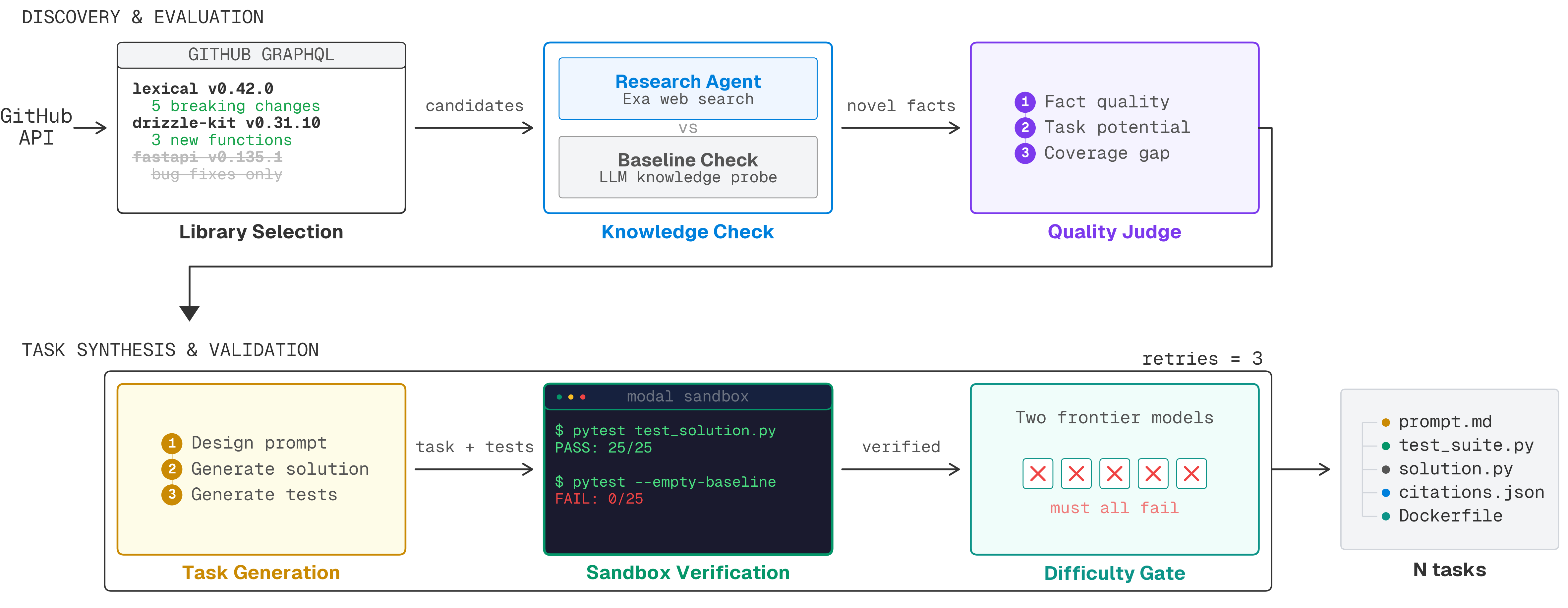
We applied the following heuristics to our seeding methodology:
- Library selection: Identified relevant libraries (>200 GitHub stars) with releases after August 1, 2025. Each release must include at least three breaking changes or new functions; releases that only included minor notes, internal refactors, or bug fixes were dropped
- Knowledge check: Queried a frontier model on the API changes introduced in the release (no web access). In conjunction, deployed multiple research agents powered by Exa's
type:deepsearch to extract concrete behavioral deltas. If the base model already knew what the research agent found, we dropped the candidate - Quality judge: Scored the research output on several dimensions, and only kept tasks containing concrete changes with working code examples
- Task generation: Generated a task prompt, solution, and test suite using the novel facts
- Sandbox verification: Inside a Modal sandbox, we verified the solution passed the test suite while the empty stub failed. Tasks where the tests did not discriminate between the two were dropped
- Difficulty gate: Two frontier models attempted to solve the task from just the prompt using up to 10,000 tokens of reasoning. We ran each model's solution against the public test suite and hidden discriminators. If any model fully passed, we hardened the task up to three times, and rejected the task if it still passed
Although tool-enabled models outperform their non tool-enabled counterparts, we empirically observed that these constraints provided a strong signal for distinguishing search quality across providers.
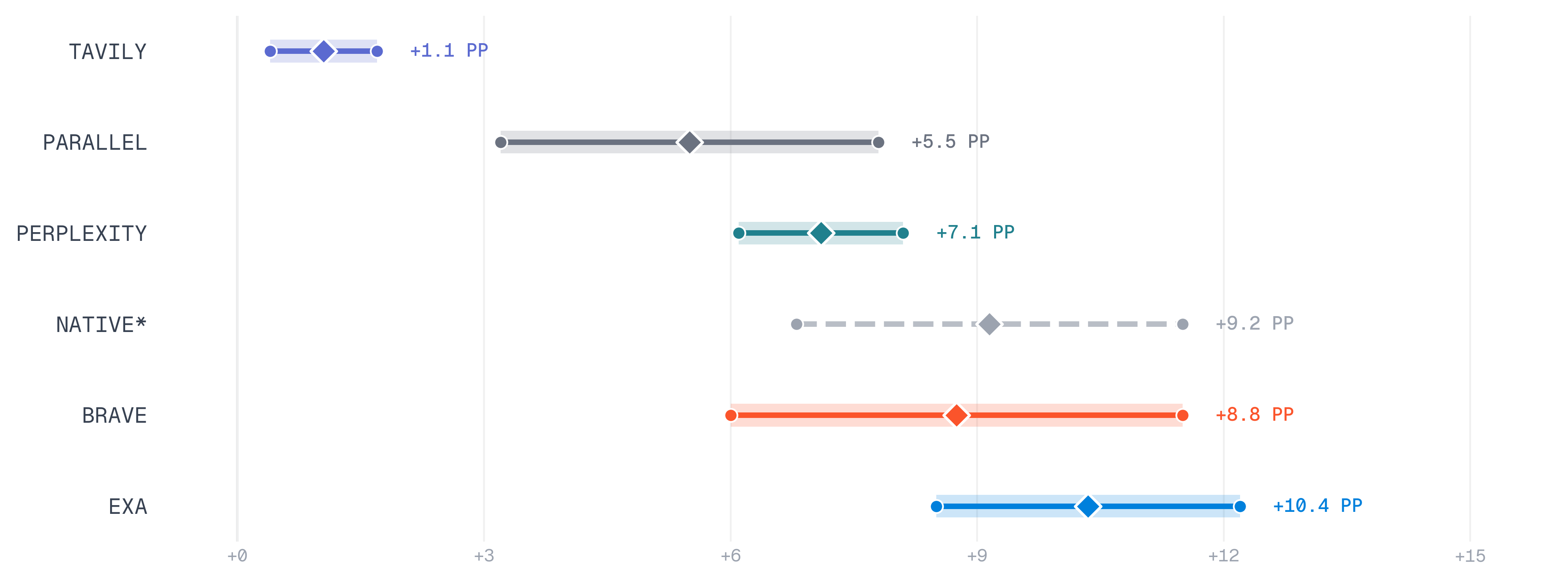
We ran multiple rollouts per provider across several frontier models. Each line shows how much that provider's pass rate improved over the no-search baseline; diamonds mark the median. Wider distributions indicate less consistent gains.
#Conclusion
WebCode both identifies and fills a critical gap in the current state of web search evals for coding agents, and demonstrates the importance of evaluating both contents and retrieval quality.
While there are further improvements to be made, we hope that open-sourcing these evaluations will help uplift the current state of code search across the industry.