Exa Highlights: Quality, Token-Efficient Search
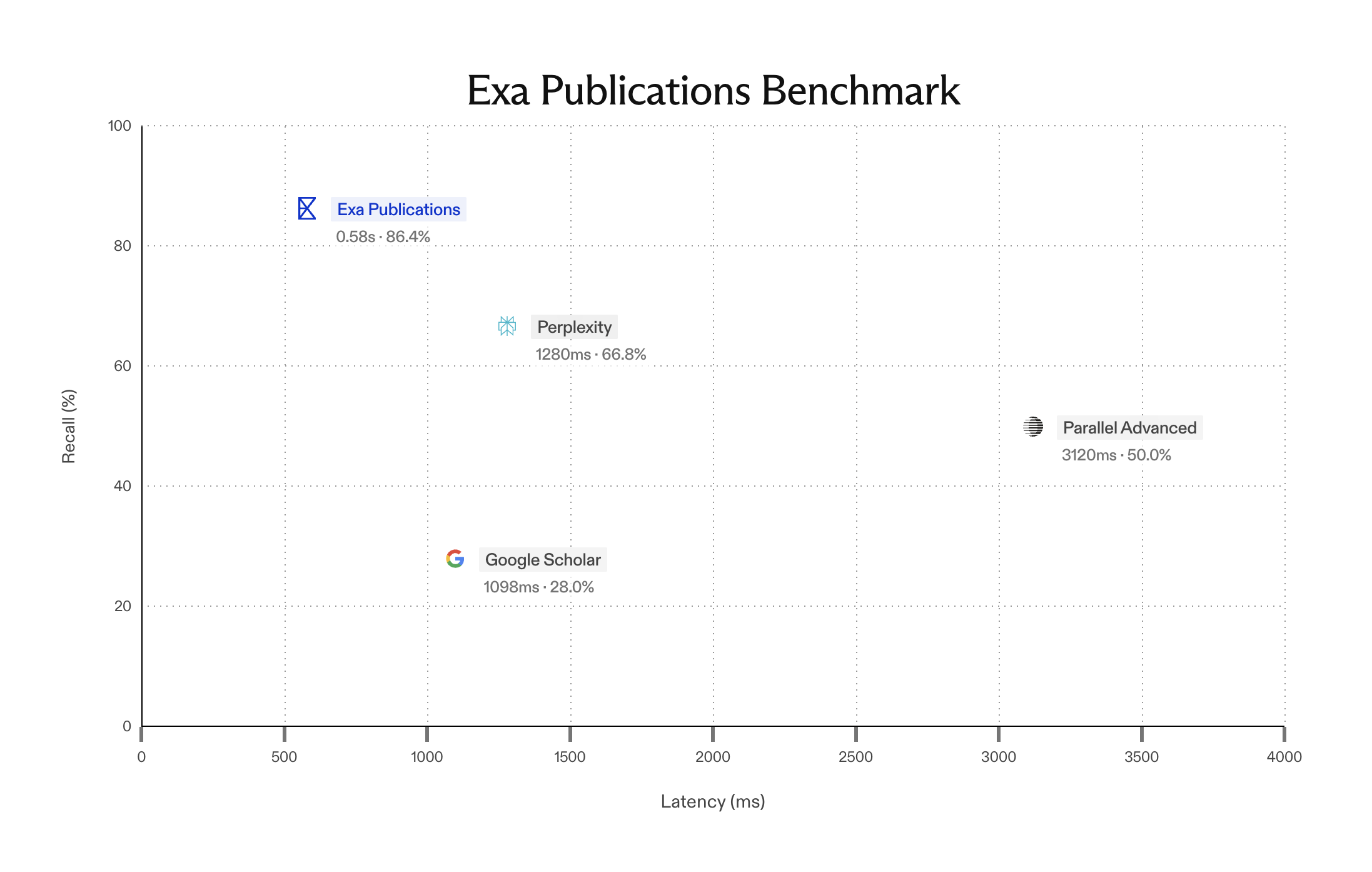
Agents use Exa for web grounding: searching the web and reasoning over the contents from those pages to give informed responses. Recent research efforts at Exa have led us to improvements in highlights. Highlights are snippets from a page, that now offer higher quality results for ~94% fewer tokens on some evals, significantly reducing costs and leading to latency benefits.
We've found this is especially important in agentic search use cases, where doing multiple rounds of search is the norm and reducing context bloat is critical. Dense excerpts allow agents to effectively reason and achieve higher accuracy.
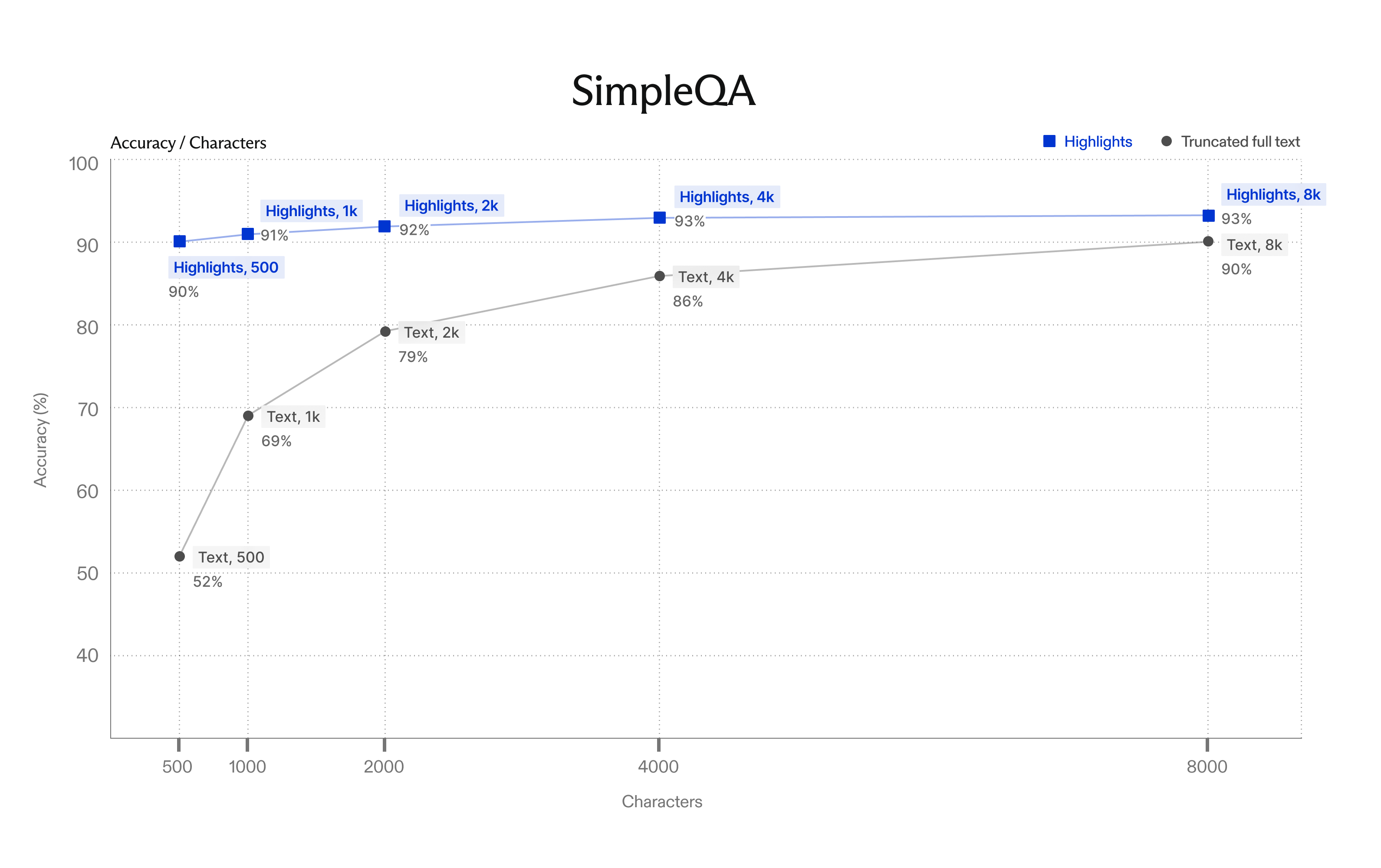
On benchmarks like SimpleQA, 500 characters of Exa's highlights match the accuracy of the first 8000 characters of the page, and use 16x fewer tokens. In addition, we found that 4k characters of highlights is better than 32k characters of full text.
Extract relevant excerpts
Today's highlights model is the product of many rounds of research. We explored a wide range of architectures and training recipes before landing on the current approach.
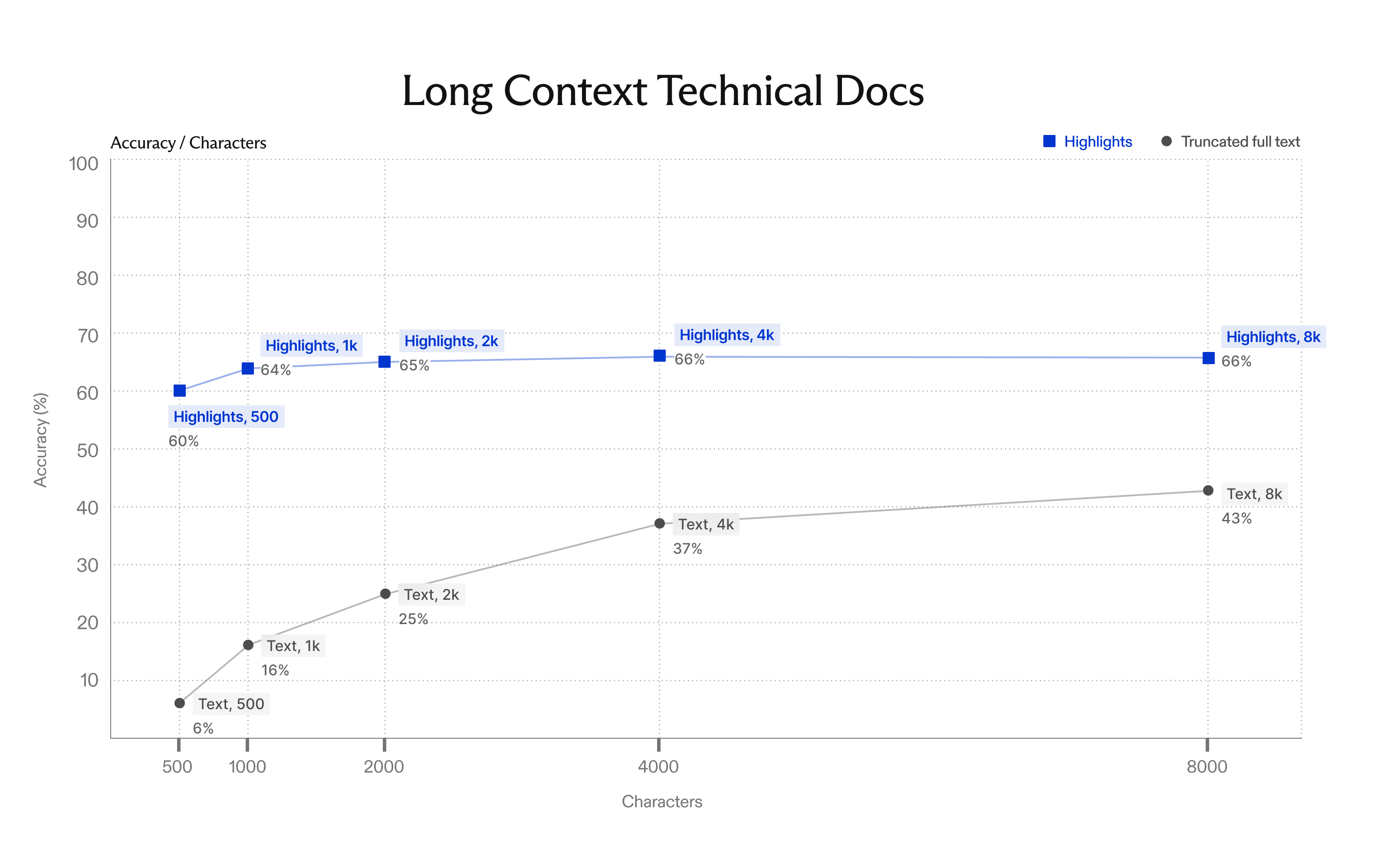
Highlights are Exa's in-house method to extract the most relevant excerpts from web pages. They run for every request to maximize relevance to the query (not cached!) and complete in under 100ms. We've recently made significant improvements on technical coding docs and long-context documents like API references, SDK docs, specs, and research papers, where the right answer is a single passage buried in tens of thousands of tokens of boilerplate. On pages that long, Exa's highlights still surface the relevant excerpts, with a significant gap at small context budgets (60% vs 6% at 500 characters).
The engine behind Exa's agentic products
Highlights don't just power the public Highlights API. They're also the retrieval substrate inside Exa's own agentic endpoints: /answer, Deep, and Websets. Every iteration of those agent loops reads highlights, not raw page content. That's one of the reasons our agentic products are Pareto dominant on latency, cost, and quality against competing systems. We have more improvements in the pipeline, on both the evals and training sides.