Introducing Deep Max: State-of-the-Art Agentic Search
Introducing Deep Max
Today we're launching Deep Max: our highest-quality agentic search endpoint. Deep Max combines frontier LLMs with dozens of parallel calls to Exa Search to answer the hardest research questions on the web.
It hits state-of-the-art accuracy on every popular agentic search benchmark, and does it up to 20x faster than the closest competitor. Deep Max releasing soon, reach out to our team about usage and pricing.
Evals
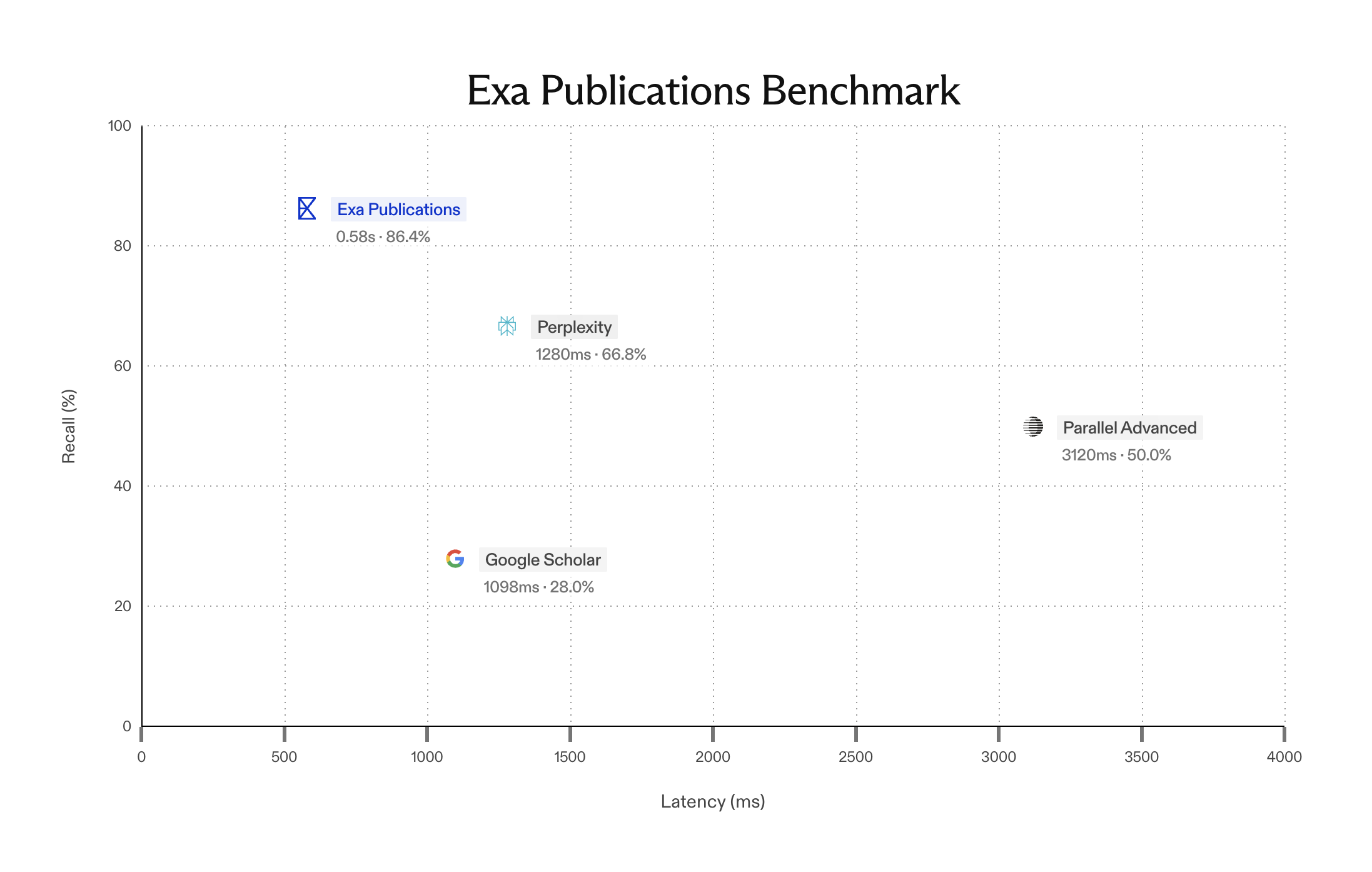
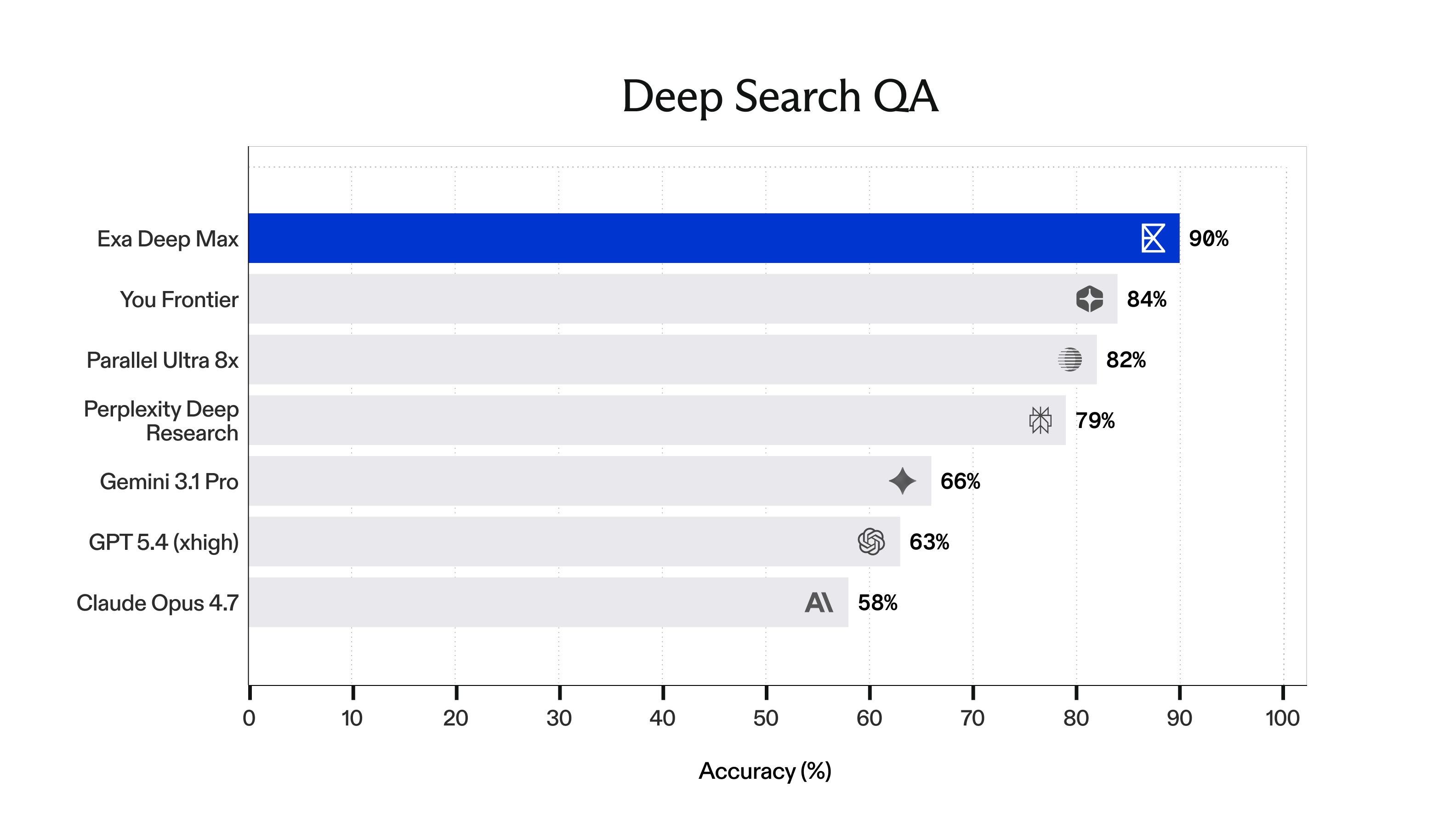
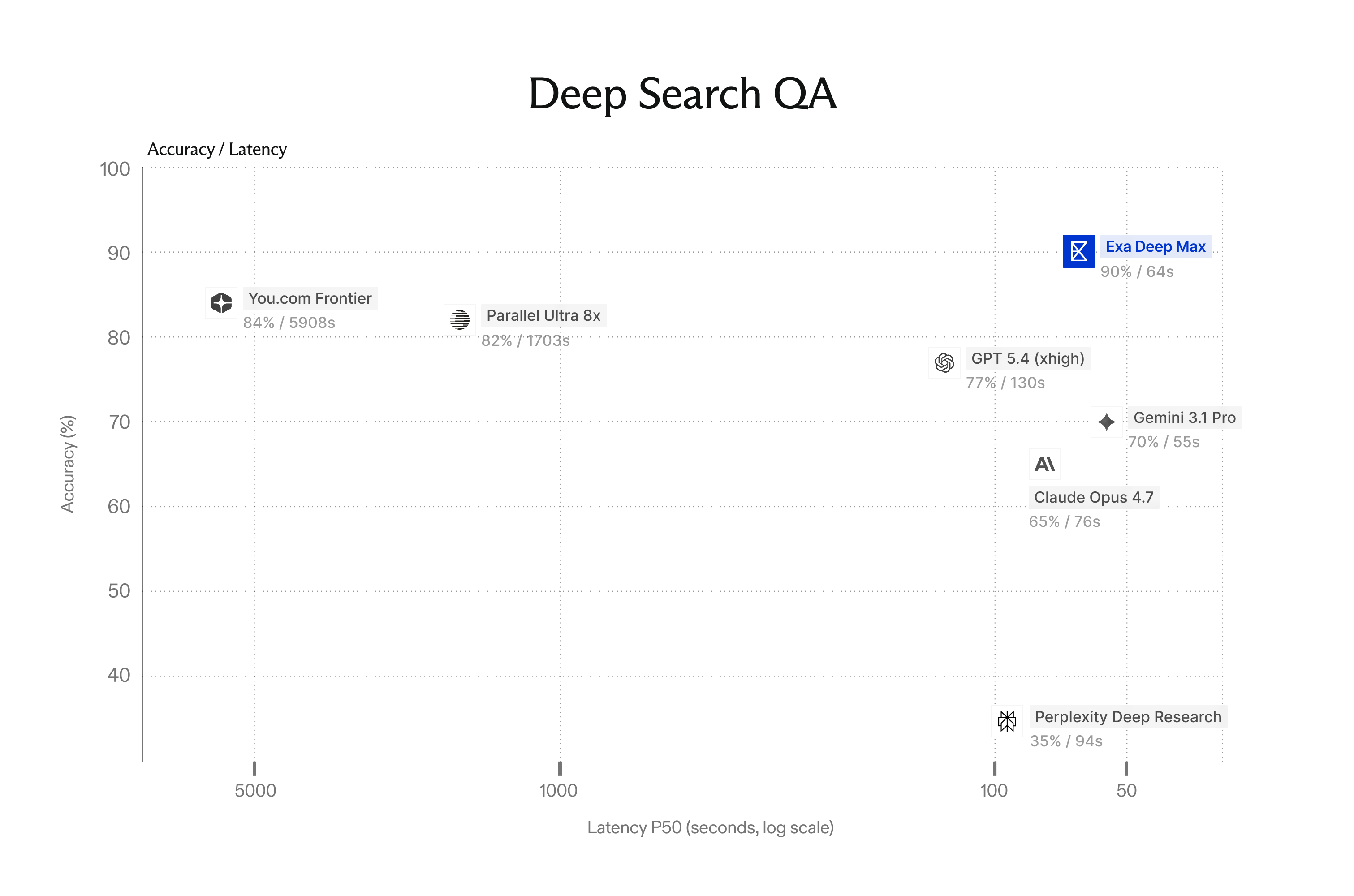
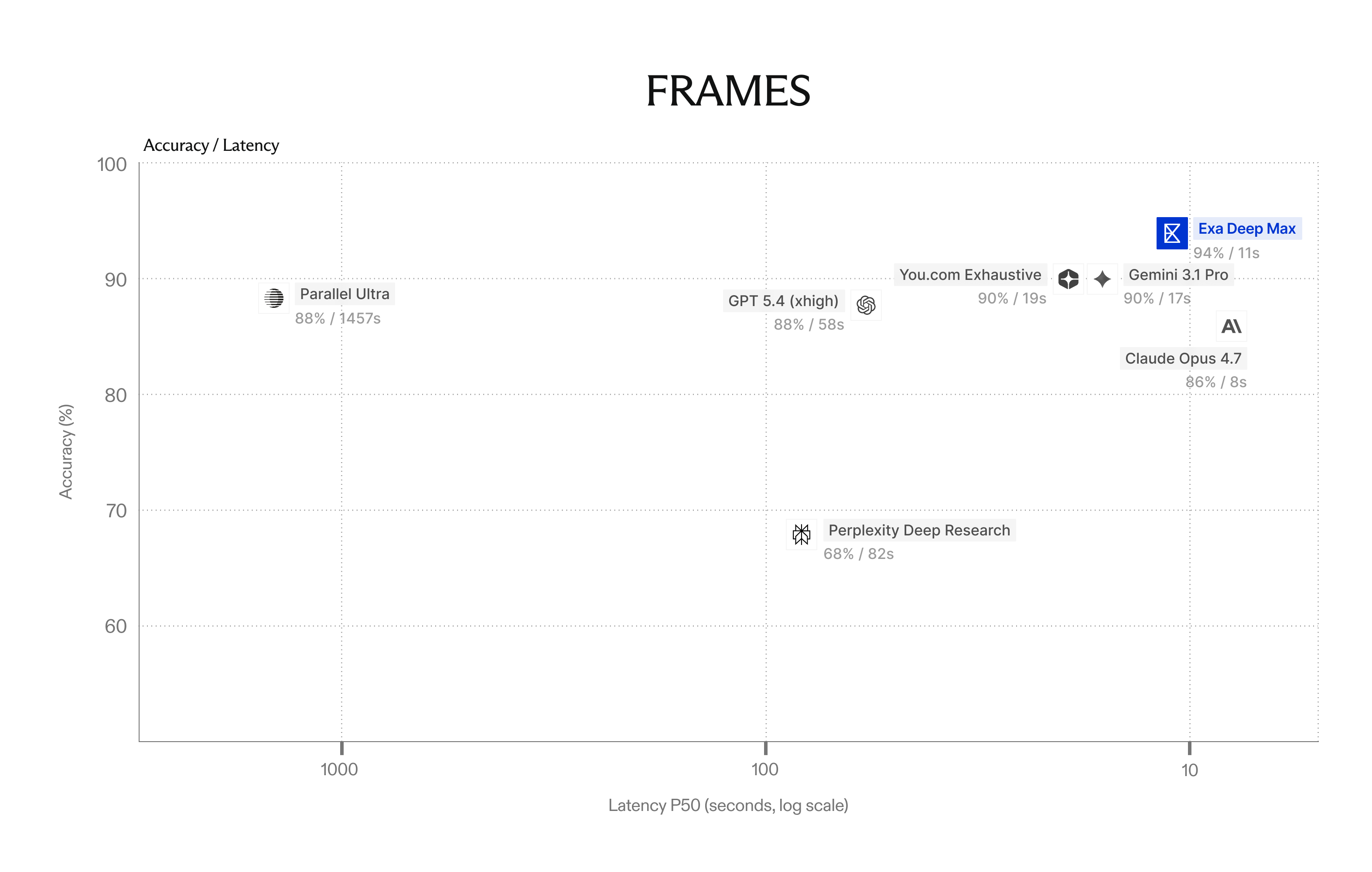
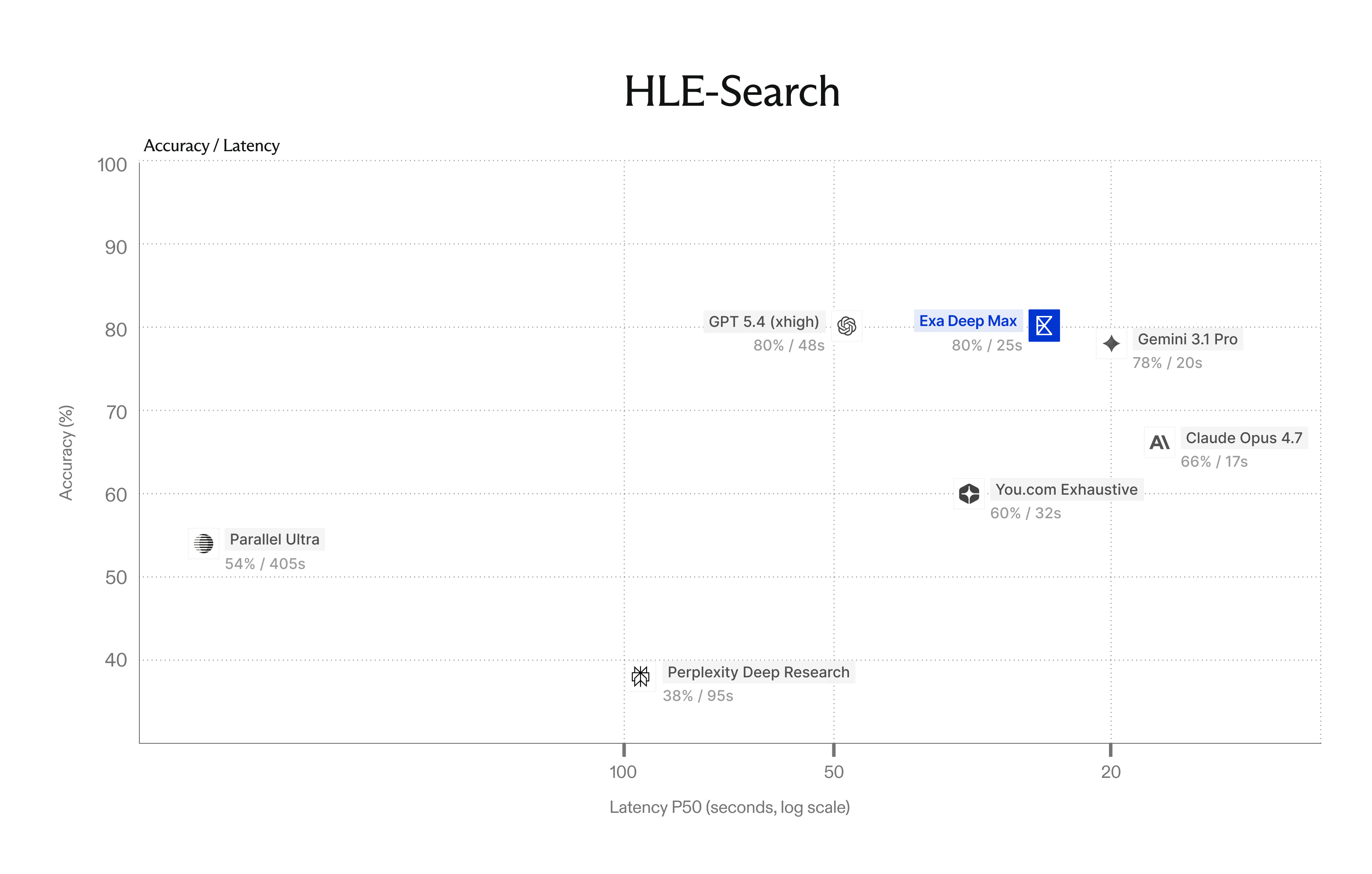
We benchmarked Deep Max against every major agentic search system (Parallel Ultra, You.com Frontier, Perplexity Deep Research), as well as frontier LLMs (GPT 5.4, Gemini 3.1 Pro, Claude Opus 4.7) running their own native search tools.
On all three evals, Deep Max is up and to the right: higher accuracy, lower latency.
Why it's so fast
A typical Deep Max query finishes in tens of seconds, not tens of minutes. Three things make that possible:
Parallel tool calls. Modern LLM SDKs fan out search and contents calls in parallel, each targeting a different angle of the question. The model aggregates as results come back.
Token-efficient contents. Exa returns page text compact enough that the model spends its context on reasoning, not on re-reading headers and nav bars. Highlights guide the model to the right pages; full crawls back the final answer.
Fast in-house search.Every tool call hits Exa's own search stack, which returns results in under a second. At dozens of calls per query, that compounds into a very different user experience than orchestration layers built on older, slower search APIs.
Reach out to our team about usage and pricing for Deep Max.
Where search is going
A primary bottleneck in agentic search is the search tool itself: how broad the index is, how clean the page text is, how fast the results come back.
AIs will soon search the web more than humans, and those agents need search that is fast, accurate, and honest about what's on the page. Deep Max is the most advanced, highest compute version of search on Exa.
We're hiring. Come help us build it.