State-of-the-art web search API

At Exa, we've built a web search engine from the ground up for LLMs to use, powered by our own custom search models. We're excited to release initial benchmarks showing Exa is state of the art among search providers on representative evals for both RAG and classic search applications.
SimpleQA
SimpleQA is a recent benchmark from OpenAI that measures how well LLMs answer short factual questions. Each question was designed to elicit hallucinations from the LLM. We run this evaluation with LLMs given access to web data, and find that as expected RAG gives a significant improvement across the board in factuality -- but with differing performance between providers.
We run the eval against different RAG providers and search APIs, using as standardized an evaluation setup as possible:
- For Exa, we use simple, prompted off-the-shelf LLMs -- gemini-1.5-flash to generate the search query, and 4o-mini to generate the answer from the results.
- For Bing, we pass the SimpleQA query and use 4o-mini with the same prompt to summarize.
- For Perplexity, we use Sonar-Pro, their flagship API for web RAG. We pass the SimpleQA query directly to Perplexity.
- We use GPT-4o as a baseline without web access, scoring the output given the prompt as in the original SimpleQA benchmark.
For each provider, we try to get the best score with that provider’s API. For fairness, if the provider has a public result on SimpleQA, we report the highest number between our results and theirs.
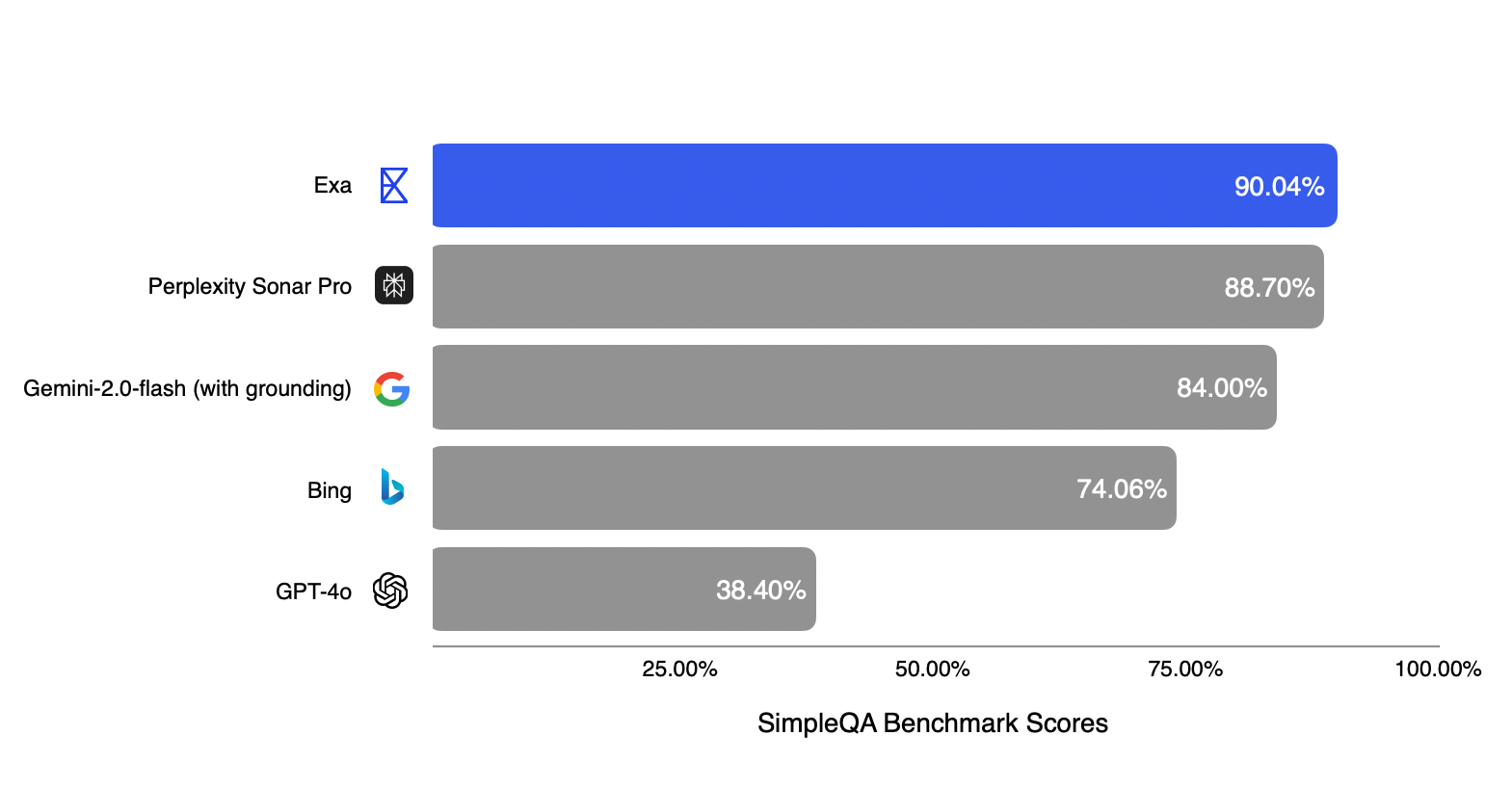
We’re happy to see Exa top the charts on the SimpleQA benchmark, especially given the simple setup for the generation. We're not surprised, since Exa's search engine was designed from scratch to be used by LLMs. Simply dropping Exa retrieval into your existing LLM solution can give you SoTA factuality, with minimal prompting effort.
MSMARCO
In addition to SimpleQA, we wanted to create another eval that tests the underlying search quality of Exa, not just the quality of the RAG answers.
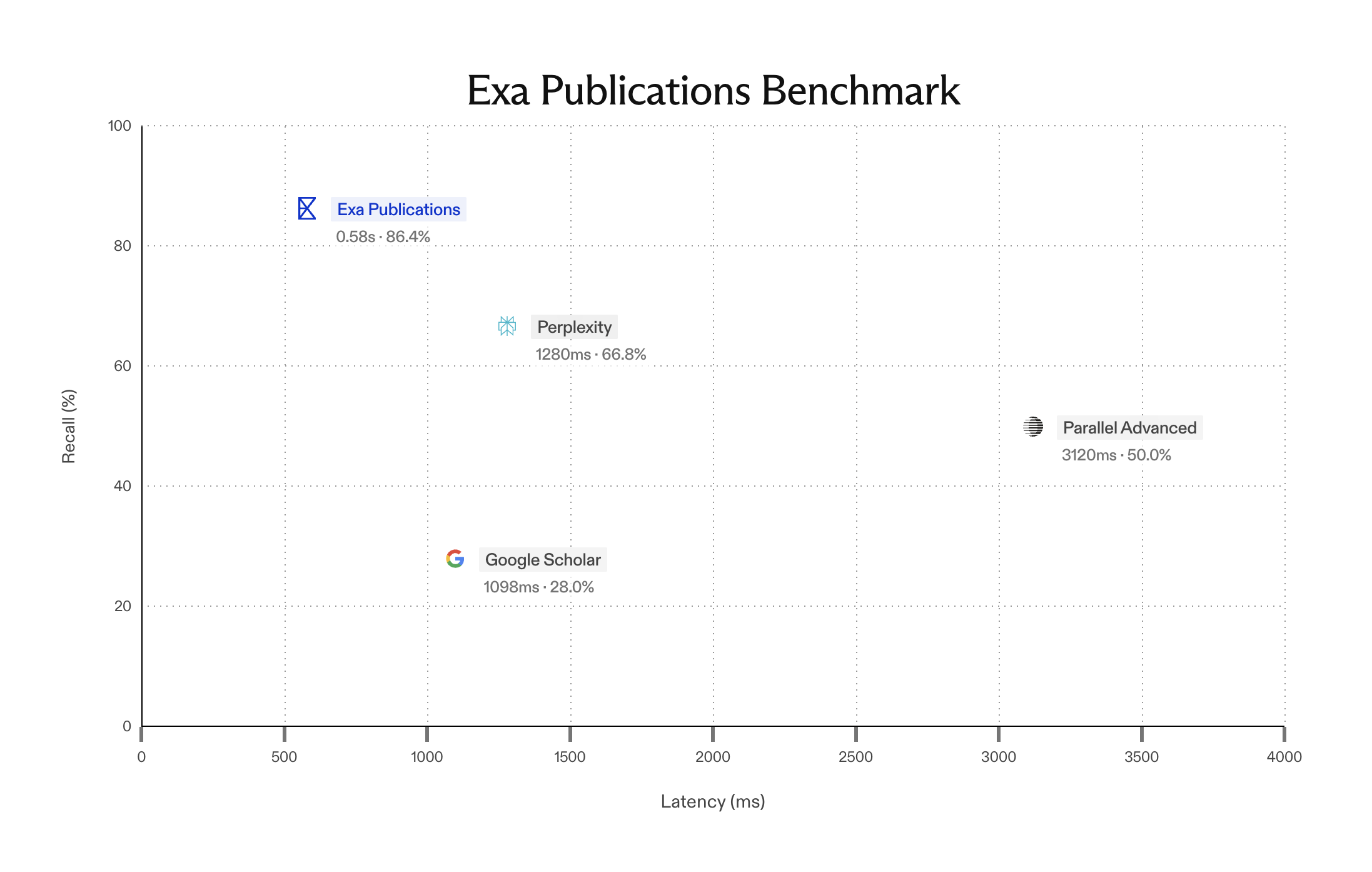
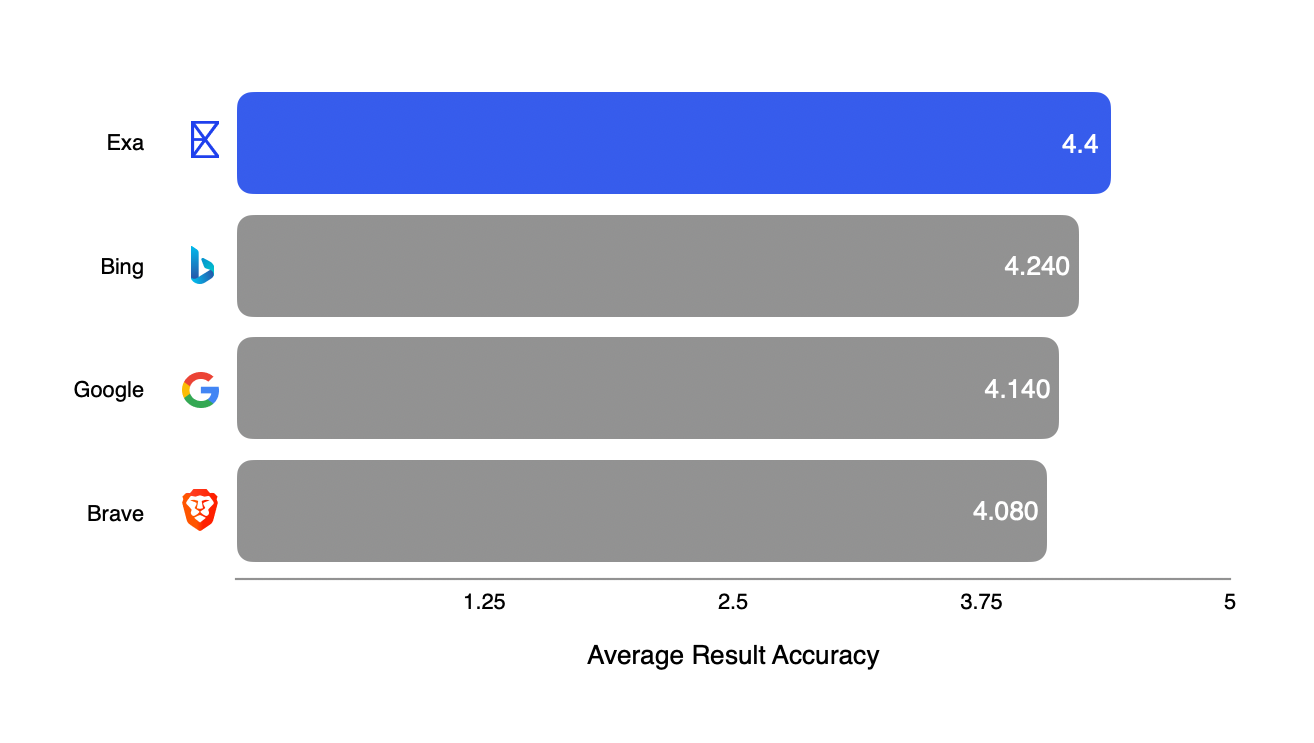
MSMARCO is a canonical query and labelled document dataset in information retrieval (IR) based on Bing searches. Typically, MSMARCO is used to benchmark IR system retrieval over the MSMARCO document index. However, in order to compare to public providers with varying indexes, we couldn't rely on the labelled documents, and instead use an LLM-as-Judge to evaluate the results returned from each search engine directly. While this approach is necessarily approximate, LLM grades in IR are found to have high correlation with human grades.
To test the accuracy and helpfulness of different API providers for downstream RAG, we take a random sample of 1000 queries from MSMARCO, pass them into each search API provider, and grade the results + any available content snippets with GPT-4o on a scale of 1-5, based on the following prompt:
You are a search result evaluator. Your job is to examine multiple search results in the context of their queries. For each result, you must produce a numerical score based on how accurate and helpful the result is. Use the following 1 to 5 scale (floats allowed, e.g. 2.5 or 4.7 are valid):
1 = Irrelevant - The content is unrelated or only trivially related to the query. - Provides no helpful information
2 = Somewhat relevant - Mentions the topic but includes little useful detail. - Could be partially out of scope or partially incomplete
3 = Moderately relevant - Reasonably addresses the query's main topic or question. - Has some factual information but might be too generic or incomplete
4 = Highly relevant - Provides detailed, focused, and mostly accurate information about the query. - Will likely satisfy most user needs without extensive extra research
5 = Exceptionally relevant and comprehensive - Extremely thorough, accurate, and directly addresses the core question. - The best possible result in terms of clarity, detail, and correctness. For each result, output exactly one line in the format:
SCORE:x where x is the float score (e.g. SCORE:4.7)
We find that in this setup, Exa is state of the art in end to end retrieval.
Future Work
We recognize that these are only a small, incomplete set of the possible benchmarks to run. We plan on curating and releasing many more benchmarks to test search quality in challenging, real world use cases, as well as adapting more benchmarks from the rich IR literature for black-box evaluation of public search providers.
Search requests are extremely diverse and it’s difficult to find public datasets that capture all that diversity. Check out our Websets eval for a totally different type of search eval.
If you're interested in testing Exa for your use case, you can integrate Exa with a few lines of code here.
If you're interested in building brutal evals, and then saturating them, come work with us!