Search that's >20x better than Google for complex queries

We're excited to announce that our new search product, "Websets", retrieves over 20x more correct search results than Google on our benchmark of complex queries.
While Google is great for simple searches, it's quite bad at complex ones. For example: "find me software engineers in the Bay Area who have a blog" or "startups in NYC with more than 10 employees working on futuristic hardware"
We built Websets to enable these extremely valuable queries. For each search, we deploy an army of agents that use our custom embedding-based search algorithm to retrieve a precise and nearly comprehensive list of people, companies, news articles, or really any entity on the web that you want.
In this post, we walk through this benchmark. We test Exa Websets, Google, and OpenAI's recent Deep Research. We find Exa does remarkably better than both.
Evaluation Method
Because Websets is designed specifically to search for entities with multiple criteria – and there does not exist such a benchmark online – we needed to create the benchmark.
Our goal was to create a minimally-biased benchmark of queries. Using humans to create this would definitely have introduced bias. So we decided that one-shot sampling from o1 would work the best.
We came up with a single prompt and asked o1 for 200 queries. We were careful to write this prompt once and run it once, to avoid any potential bias from prompt tuning.
Here are some example queries:

We then fed these queries to Exa Websets, a Google Search API, and OpenAI's Deep Research.
For Google and Exa, we asked gpt-4o to grade both sets of results. For each query, gpt-4o created the set of criteria required to pass. gpt-4o then evaluated whether each result passed all the criteria. For example, when the query was "nutritional advice that experts have reversed their stance on in the last 5 years," gpt-4o created these criteria and evaluated each result based on them:
- Whether the search result clearly describes a piece of nutritional advice
- Whether that nutritional advice that was previously recommended or discouraged by experts
- Whether there was a reversal of expert stance on the advice within the last 5 years (2020-2024)
- Whether there are identifiable experts or authoritative bodies involved in the advice and reversal
For OpenAI's Deep Research, for each query, we told it to return as many results as possible in a table form and not to give a sample. Though there may exist a more optimal prompt, we did not find much variation in our testing. We then manually graded each result based on the same criteria as above.
Results
This graph below shows the number of matching results (i.e. results that met all criteria above) for Google vs OpenAI's Deep Research vs Websets (low compute) vs Websets (high compute).
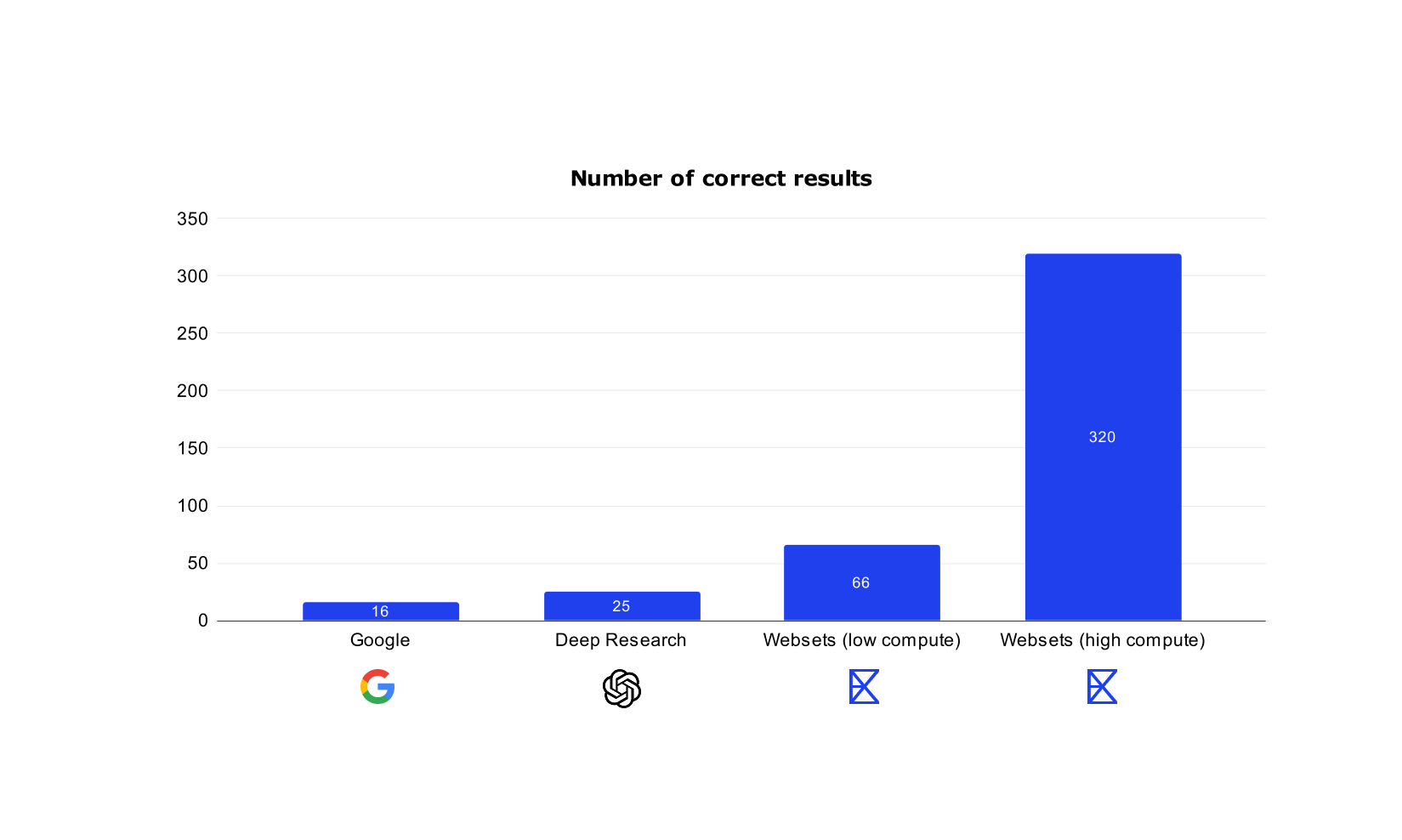
Each search engine has a different result cap. Google can only return max 100 results. OpenAI's Deep Research can sometimes return more but often stops after only finding a couple dozen. But Websets can return as many results as you want, depending on how much compute you're willing to spend.
In the low compute Websets version, we requested 100 results per query to match Google. In the high compute Websets version, we requested 1000 results. The y-axis shows the rough number of results across all the queries that met the query criteria. Note, due to compute constraints the sample size was small here, and also these search tools are changing a bit over time, so these numbers should be interpreted as rough estimates.
Google obtained only 16 correct results on average. That's because Google is doing a keyword matching algorithm that is pretty bad for complex queries. Deep research's precision is higher but struggles to find many results in the first place. In contrast, Websets (low compute) gets 66 correct results on average, because we leverage a more powerful search algorithm. And Websets (high compute) gets 320 correct results per query on average, because we leverage way more compute.
Of course, we could run Websets with 10x even more compute, or 100x more, but we think 20 times better than Google is good enough for this eval :)