Introducing Exa 2.0

Exa 2.0
Today we're announcing Exa 2.0, the next generation of our search endpoints. Exa now offers both the fastest search API in the world and the highest quality search API.
Specifically, Exa 2.0 includes three major updates:
- Exa Fast: the fastest search API in the world at sub350ms
- Exa Auto: our default search type is now much higher quality
- Exa Deep: a new search type that agentically retrieves the highest quality results
How we built it
Exa's sole mission is to build a perfect search engine.
One that always returns exactly the information you need as fast as physically possible, available through a seamless API. Today's 2.0 launch is a big step toward that goal.
To build Exa 2.0, we first needed to build a much bigger index. We now crawl + parse tens of billions of webpages and refresh them every minute.
Next we pretrained and finetuned an embedding model for precise semantic search over that index. Exa 2.0 was trained for over a month on our 144x H200 cluster and used new embedding techniques we've discovered over the past 6 months.
To serve these embeddings at the lowest latency in the world required major updates to our in-house vector database. Some examples are new clustering algorithms, new lexical compression, and several assembly optimizations. All in Rust of course.
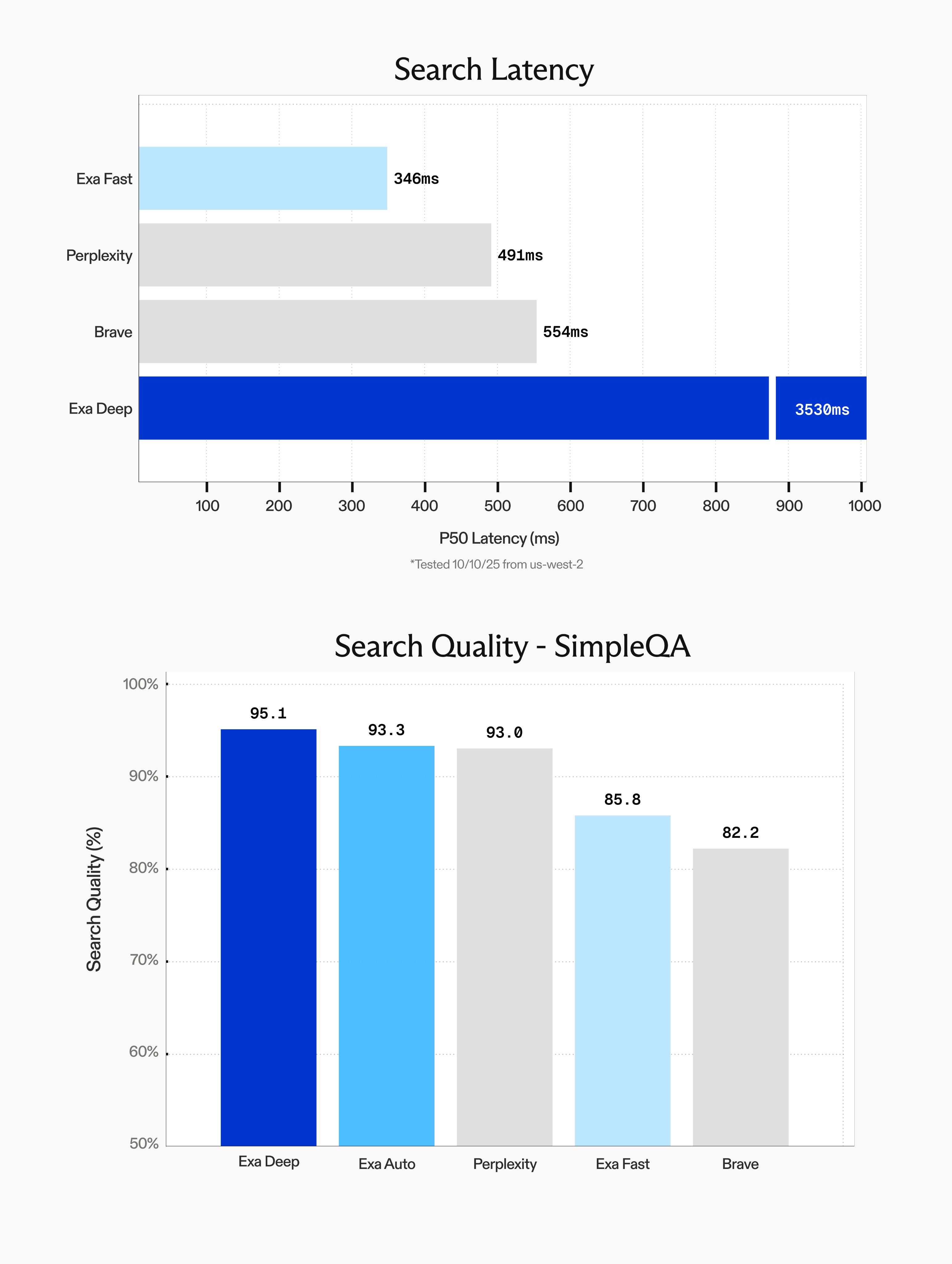
Latency
Our first API update is Exa Fast. Exa Fast now achieves lower than 350ms e2e P50 latency. This is 30% faster than the next fastest API.
In those couple hundred milliseconds, we process many billions of webpages in our index to identify the most relevant ones, then extract the web context most helpful for AIs to consume.
With this endpoint you can add near-instant search, so that your LLM doesn't wait to be grounded in the world's information. Exa already powers hundreds of latency sensitive AI companies, from financial agents to super fast chatbots.
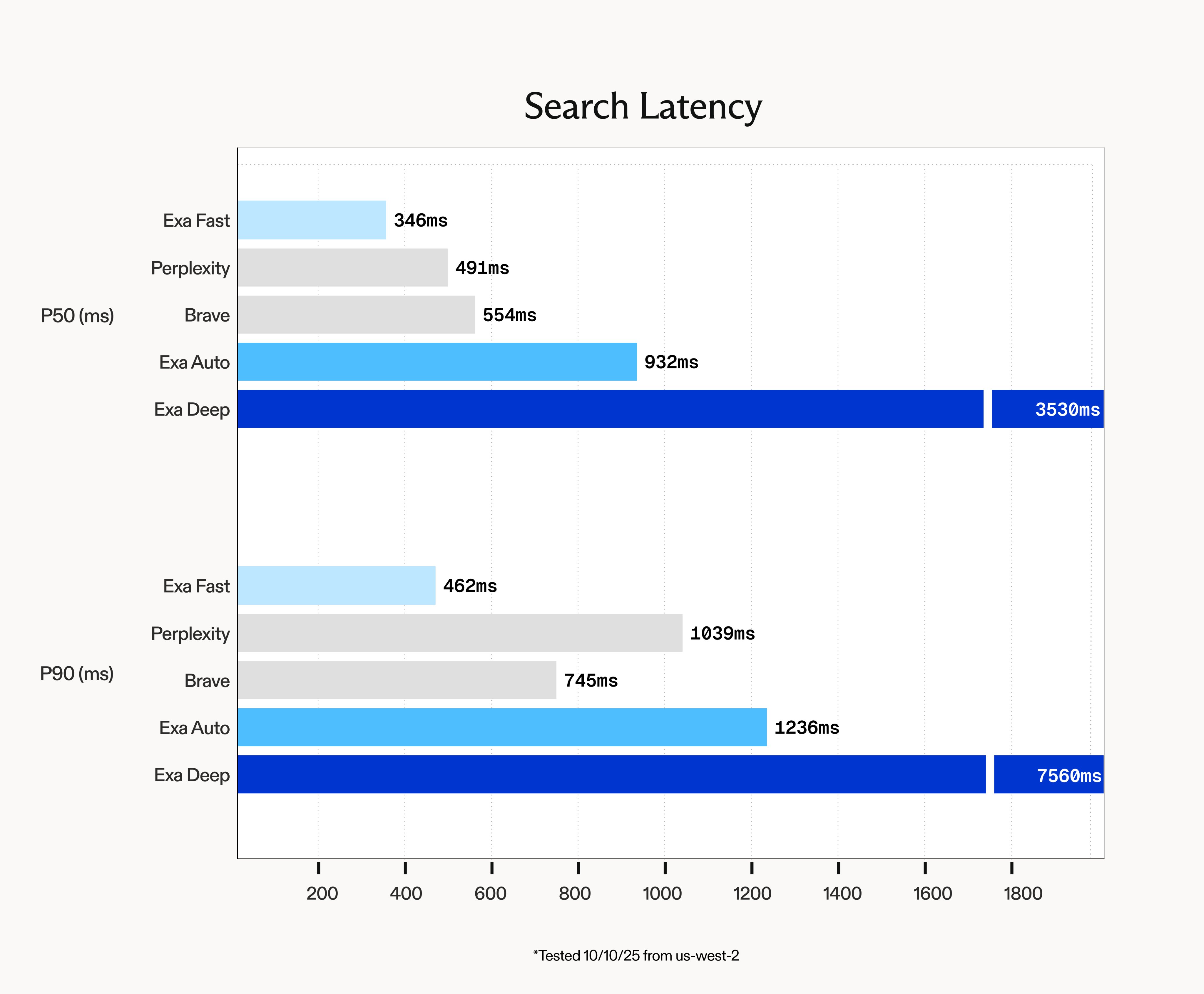
We tested these search endpoints from us-west-2 (Oregon). Here's the code we used to evaluate latency.
Search Quality
Our second API update is the introduction of Exa Deep.
Exa Deep tops nearly every benchmark we throw at it in search quality. It's a slower endpoint (3.5s P50) built on top of our faster endpoints, bc it agentically searches, processes, and searches again until it finds the highest quality information.
This endpoint is great for workloads that need the deepest information. It complements our third API endpoint, Exa Auto, which was optimized to balance latency and quality.
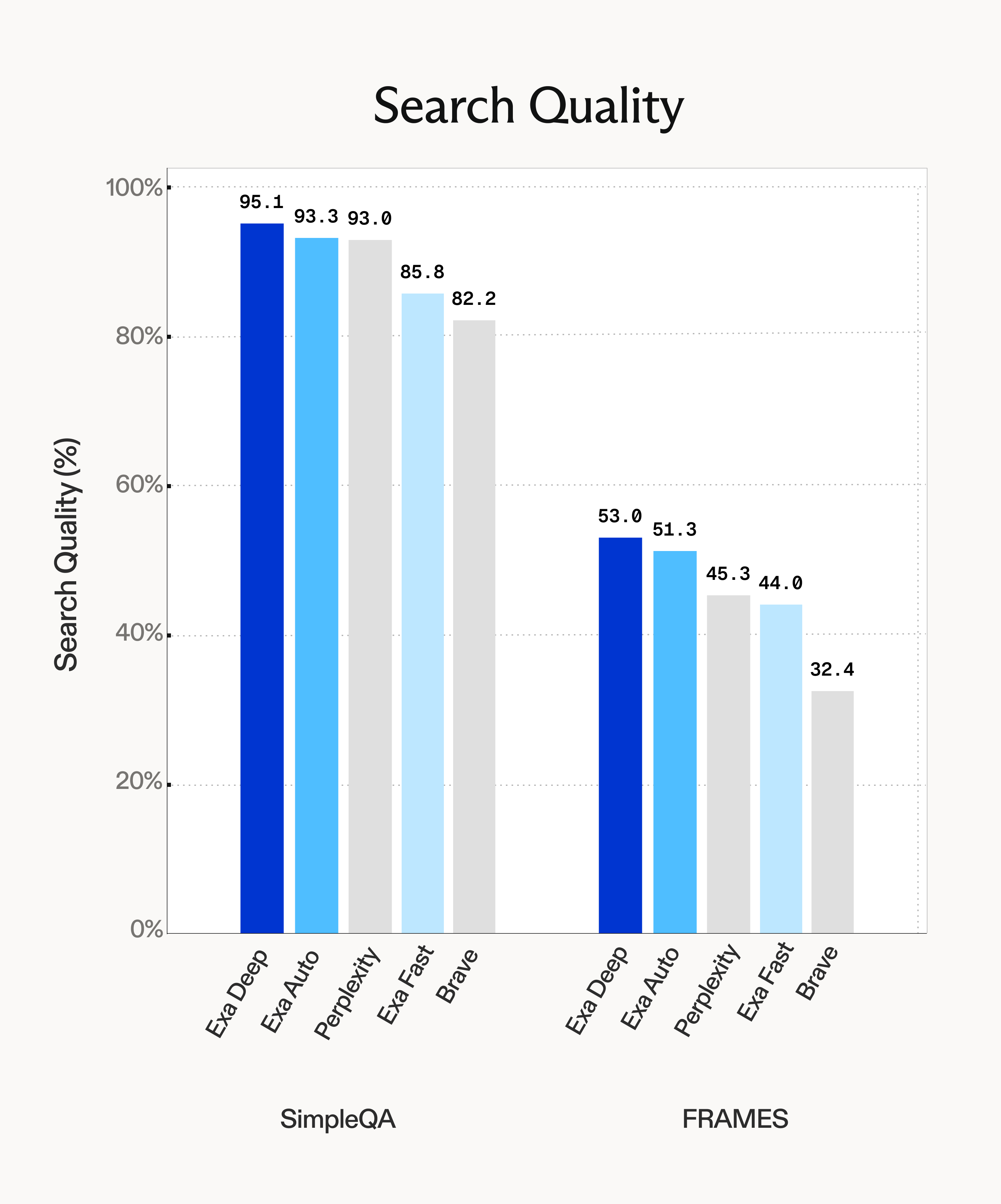
Search is a very diverse problem space. Eval benchmarks like SimpleQA and Frames test a couple types of queries, but there are many, many other types of queries that customers care about.
Here we show evals on some other benchmarks. We have many more internal ones that we'll open source soon.
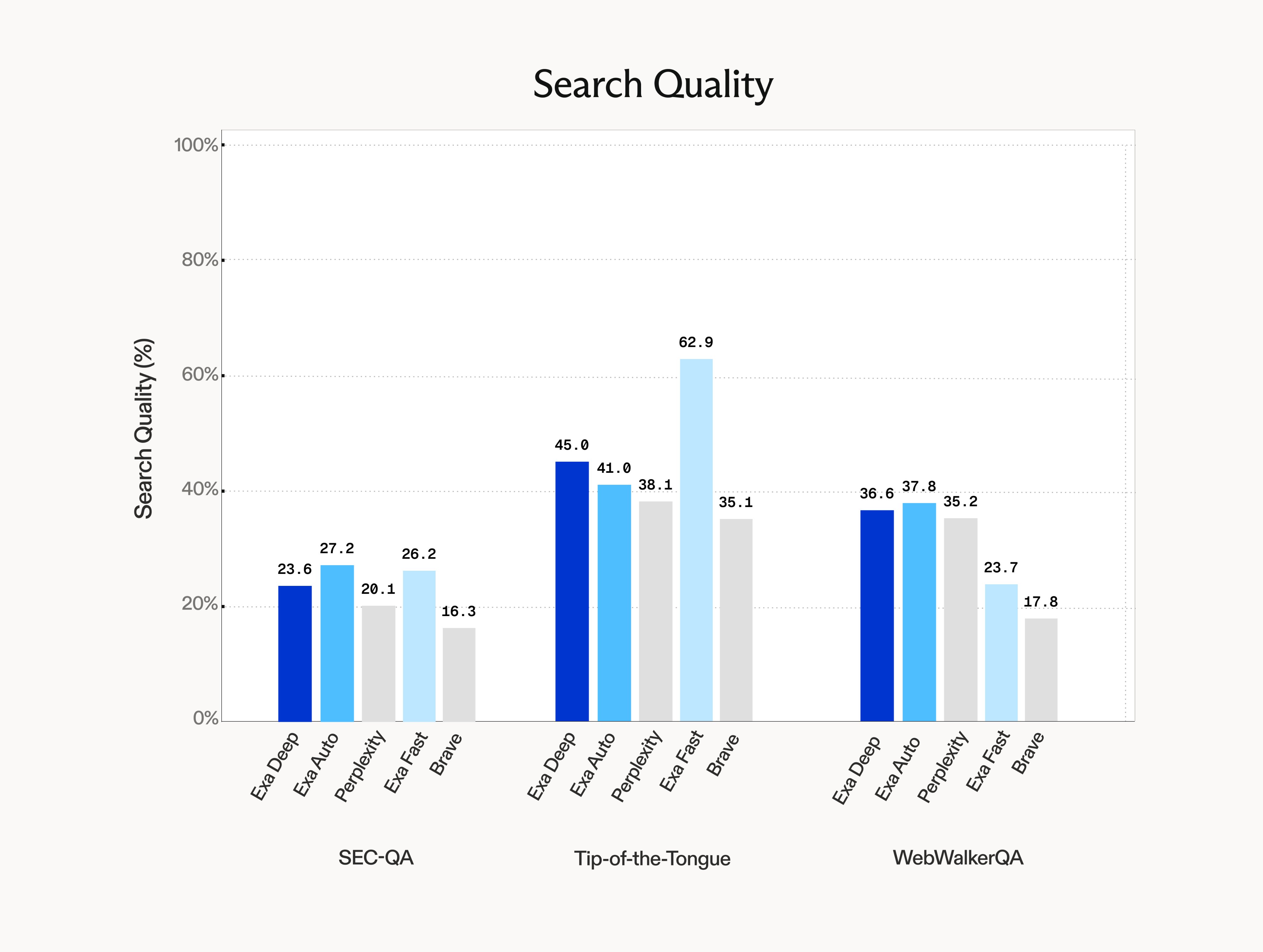
To evaluate search APIs in a RAG setting, we used the same simple LLM harness for each eval, matching the setup from Perplexity's harness . All evals were run with GPT4.1 as the RAG model and GPT4o-mini as the grader model. For fairness, where there exists public benchmarks with comparable settings, we took the max of the scores we measured and the public ones.
Future of Exa
Lastly, we're assembling a world-class team of researchers and engineers quite quickly.
If you're interested in building by far the fastest and smartest search engine the world has ever seen, far better than Google, come join the squad!


