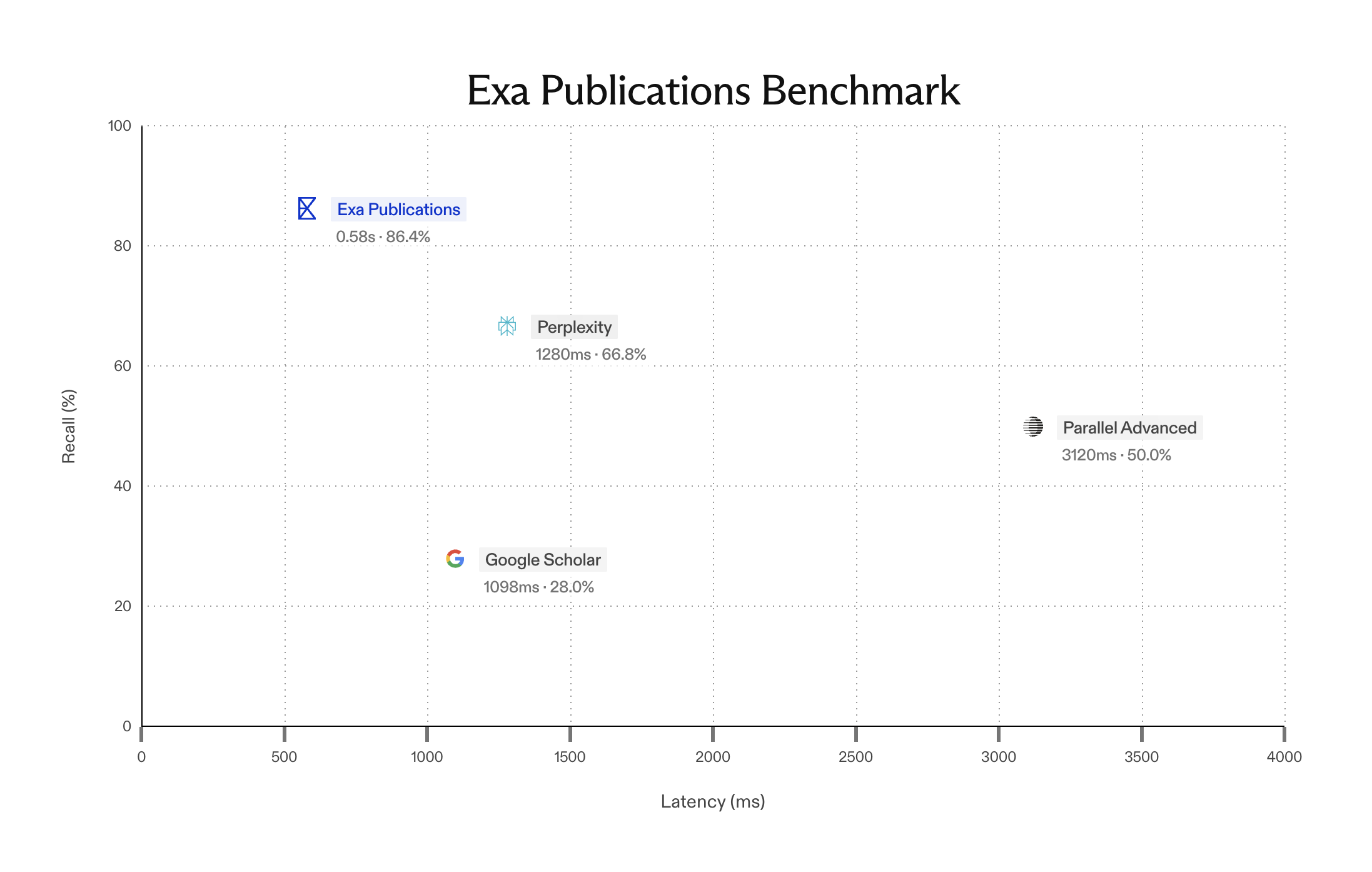
Introducing Exa's People Search Benchmarks
Introducing Exa's People Search Benchmarks
tldr: we built a new state of the art people search.
To get here, we trained our retrieval system for people search and indexed 1B+ people using hybrid retrieval that combines fine tuned Exa embeddings with Exa search. Our ingestion pipeline is built for 50M+ updates per week.
People search is especially important for sales, recruiting, market research teams, and anyone looking for specific types of profiles like investors or founders.
As part of this launch, we created an open source eval that includes a portion of the dataset to serve as a public standard for people search on the web.
We're releasing:
- A role based people search dataset (1,400 queries)
- An evaluation harness to reproduce results on your own system
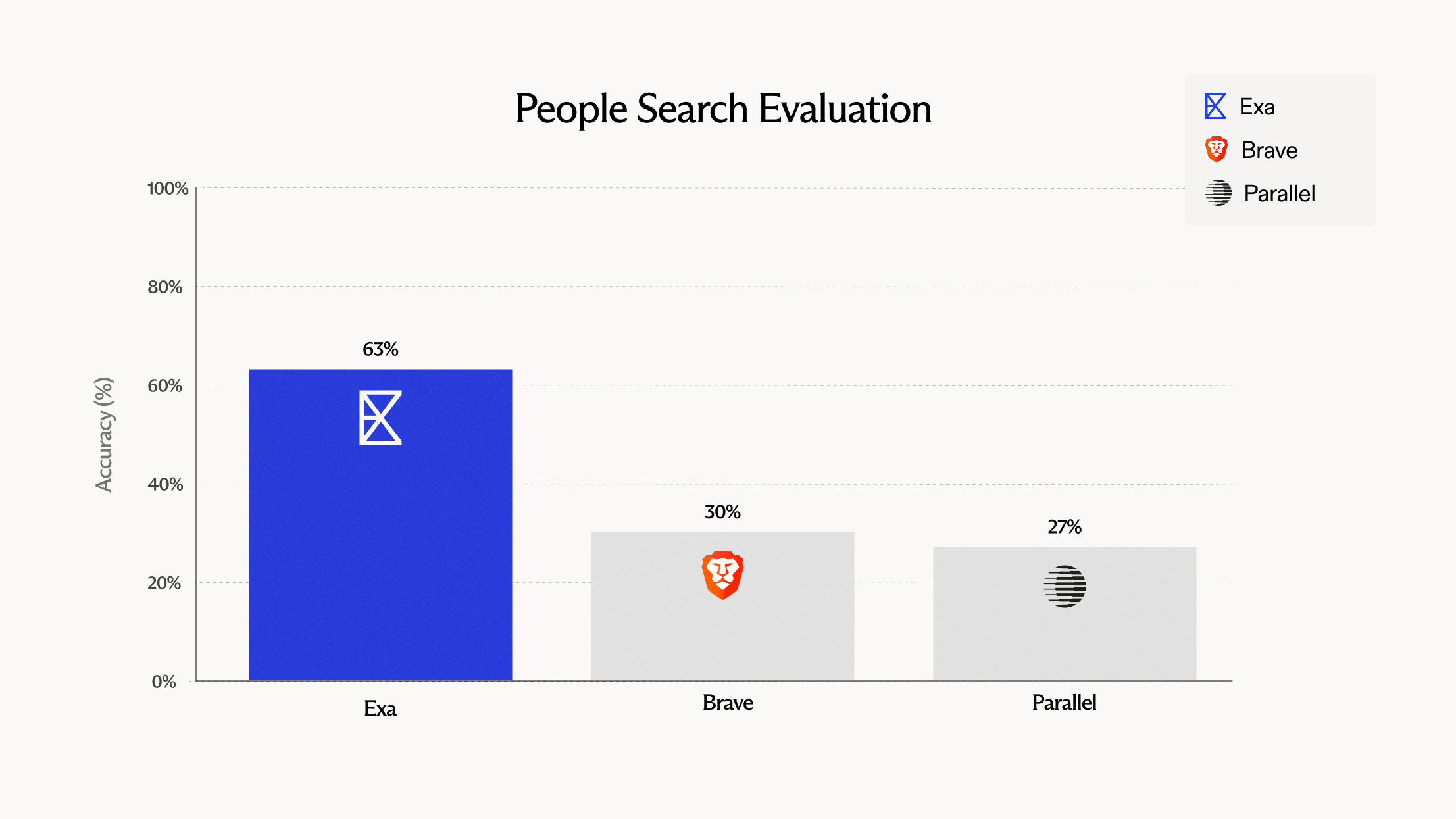
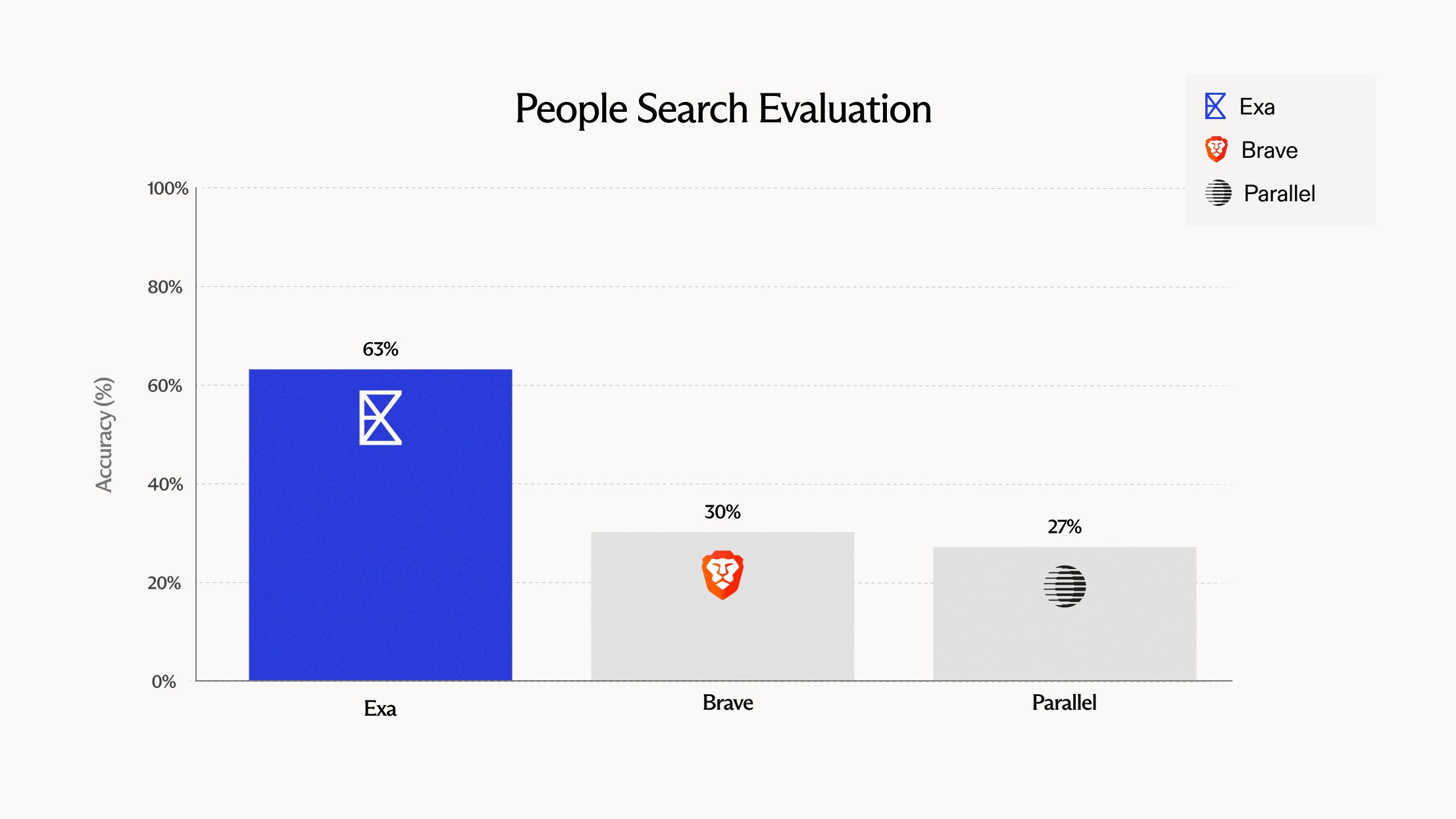
What types of people search do people care the most about?
We analyzed 10,000 historical people queries from exa.ai and clustered them to identify dominant usage patterns. 3 key categories emerged:
- Role-based search — company executive positions at specific organizations (e.g. "VP of product at figma")
- Skill or role based discovery — finding candidates by expertise and location (e.g. "Director of sales operations in Chicago SaaS")
- Specific Individual Lookup — name plus optional affiliation (e.g. "Jane Smith at Acme Corp")
Based on the above, we shaped benchmark design to test targeted lookups for a specific person and discovery for relevant profiles matching specific role, geography and skill criteria.
Data Generation
We generated role based queries for the dataset within those 2 categories using the methodology below.
Targeted lookup queries
We sampled executives and founders across 4 categories of companies.
| Categories of companies | Example Source |
|---|---|
| VC-funded startups | Founders with public profiles |
| Small-cap public (<$2B) | Executives from SEC filings |
| Mid-cap ($2–10B) | C-suite and VP-level roles |
| Large-cap (>$10B) | Senior leadership |
For each person, we generated synthetic queries that match how users search for them. A sample entry:
{
"query": "VP Operations at [Redacted Manufacturing Co]",
"name": "[Redacted]",
"role": "VP Operations",
"company": "[Redacted Manufacturing Co]",
"market_cap_tier": "mid_cap"
}We specifically selected individuals who have verifiable public profiles but aren't famous enough for LLMs to know from pre-training. This ensures we're testing retrieval vs memorization.
Role-based discovery queries
Here, Claude Opus 4.5 was used to generate a structured taxonomy:
- Industries: fintech, healthcare, logistics etc
- Roles per industry: mapped to seniority levels (IC, manager, director)
- Geographies: regions (EMEA), countries, states, major cities per industry vertical (Boston for biotech)
- Filters: years of experience specific skills
Example query:
{
"query": "mid-level onboarding specialists based in San Diego",
"role_function": "customer_success",
"role_seniority": "ic",
"geo_name": "San Diego",
"geo_type": "city"
}Evaluation Methodology
For targeted lookup, we used standard retrieval metrics like recall@k and NDCG. The person's online profile lives as the ground truth here.
For role based discovery, an LLM judge is used given there is no single correct answer. For each result, we fetch the page content and verify whether it matches the query criteria. A search for "senior software engineer in SF" for example returns 9 matching profiles and 1 person in San Diego scores 90%.
Across all search providers we ran this evaluation against, we attempted to identify the optimal configuration for people search in their API.
People Search Eval
Our People Search Eval is the first of many public evals we plan to publish. We are open-sourcing the dataset and harness so it can serve as a benchmark others can run and use to push retrieval research forward.
The current state of web search evals still leaves a lot to be desired. People search is one useful vertical, especially for recruiting, sales, and finance, but there are many other search domains where no industry-standard evals exist at all.
Our longer-term goal is to help build that evaluation ecosystem, and through it, advance the broader retrieval landscape in service of Exa's mission of building perfect search.
Try it yourself
- Open source people search benchmark
- Playground — use search type = "auto", category = "people"
- Exa.ai