Introducing Exa 2.1

Exa 2.1
Today we're announcing Exa 2.1!
We scaled our pre-training and test-time compute by an order of magnitude, unlocking frontier search API performance for both fast and agentic search.
Exa 2.1 includes two major product updates:
- All Exa search API endpoints have significantly improved in quality -- Exa Fast, Exa Auto, and Exa Deep.
- The Exa MCP quality has dramatically improved with a new deep search tool.
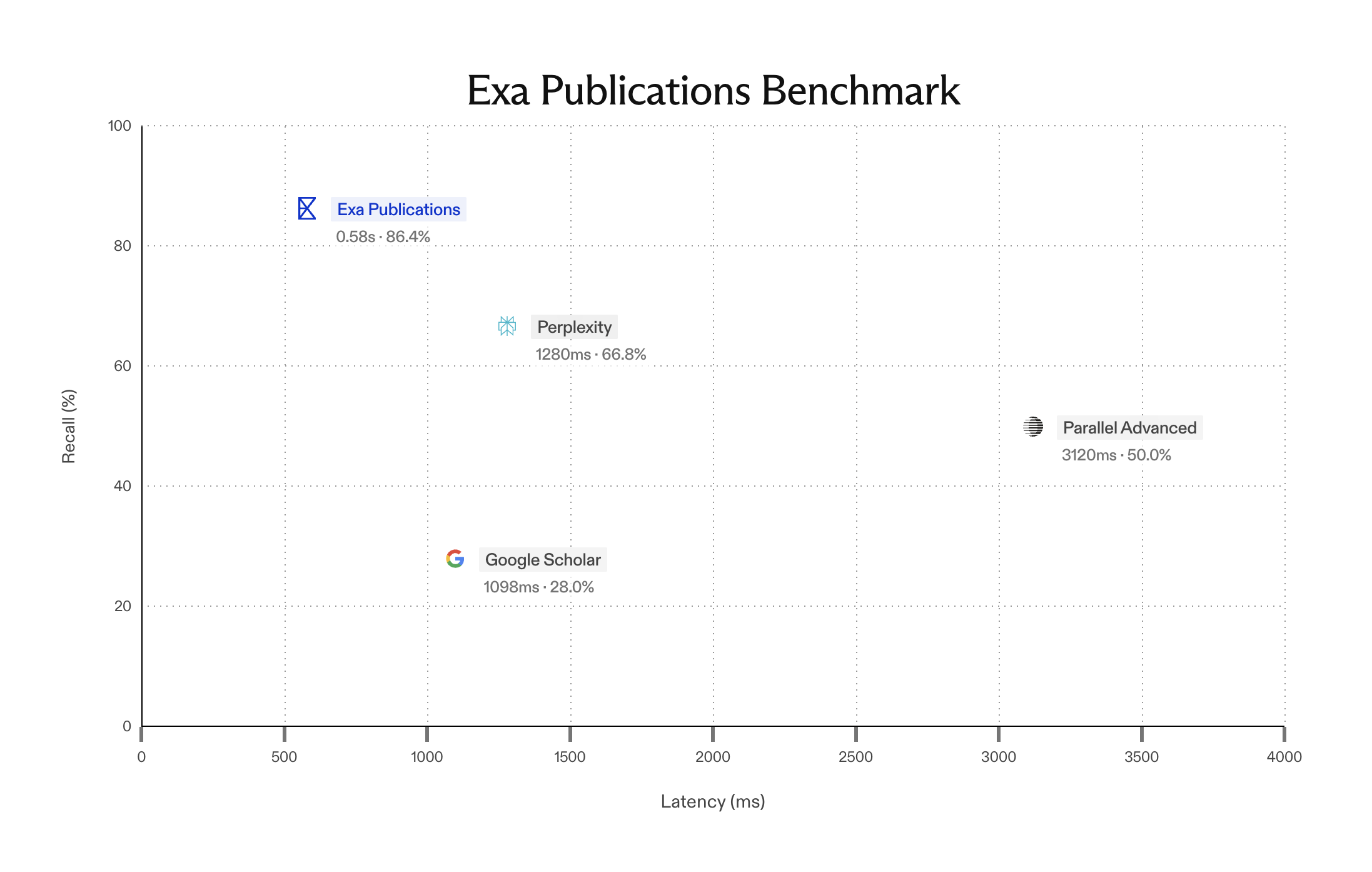
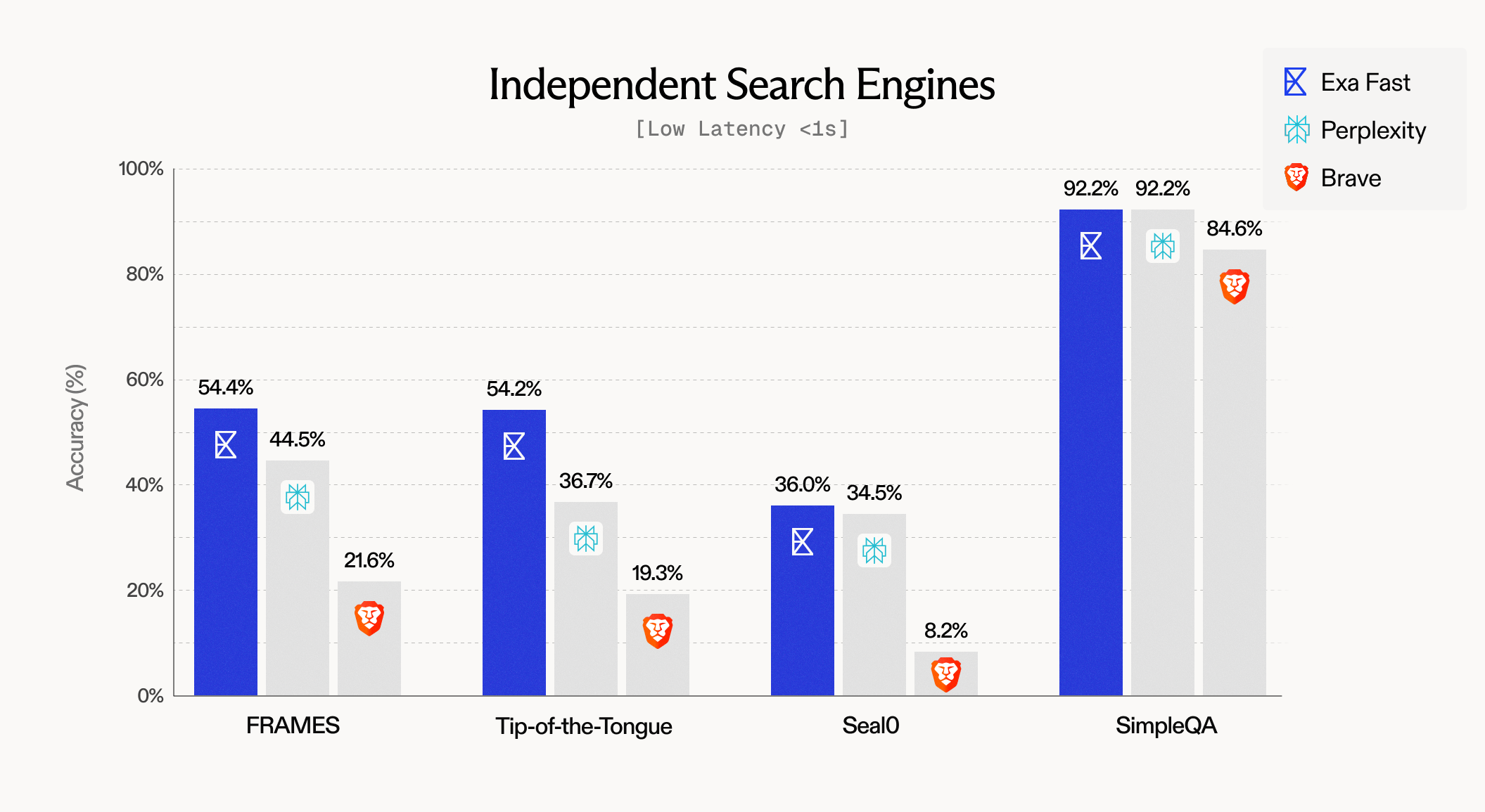
Low-Latency Evals
Fast search evals
Most of our customers need low-latency search. Exa Fast is now the most accurate search API that’s sub 500ms.
Most search APIs wrap Google search under the hood, which is why they can’t get faster than ~1000ms. We can go faster because we spent years building an independent document index and retrieval algorithm from scratch.
Agentic search evals
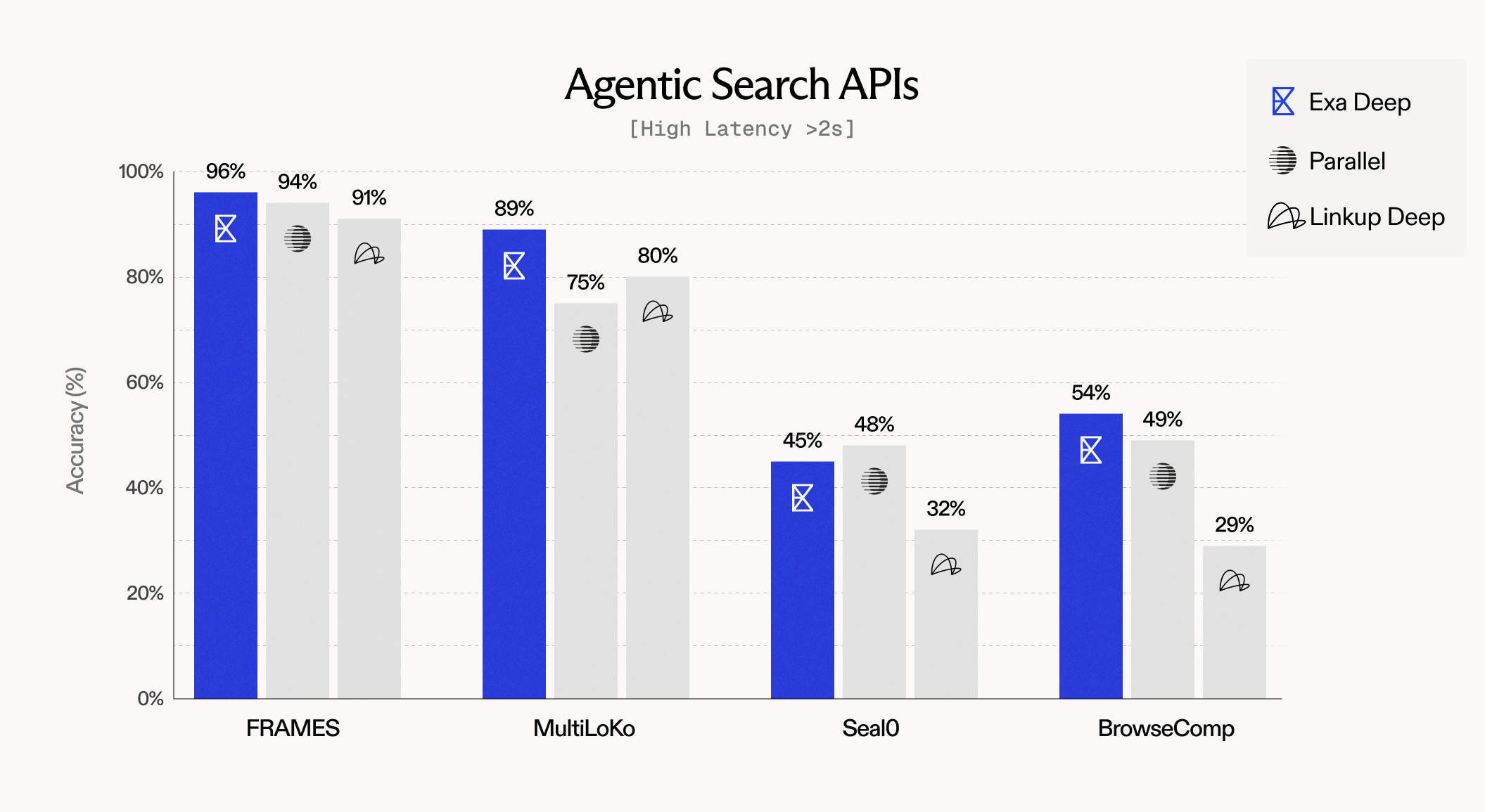
Other customers just want the highest quality search and don’t mind a few seconds of latency.
Our “Deep” search is now the highest accuracy search API on the market. It agentically searches multiple times to get the optimal results.
You can try out Exa Deep now in the API, or in our MCP server.
Eval Methodology
In order to obtain representative benchmarks for the search API's, we ran evals with two different harnesses.
In the fast setting, we ran each API with a minimal `SingleStep` harness. This harness, given a search API, LLM query, and expected answer, searches the prompt directly with the search API with the API's default settings. We pass the LLM query and 10 search results to GPT-5 mini, and use gpt-4o-mini to grade the LLM output for correctness against the expected answer.
In the MCP setting, we test how well a simple but powerful agent performs when given access to the MCP of the respective search API. This harness passed the LLM query to GPT-5, which is allowed to call the MCP up to 10 times in sequence with an appropriate query and default settings, and the final output is again graded with gpt-4o-mini against the expected answer.
Low-Latency evals were run 11/23/25 and MCP evals were run as of 11/20/25.
Building our own search engine
Building a search engine is one of the hardest technical challenges in software. It takes years of research and development to design retrieval algorithms over an index that’s many petabytes. Only a handful of companies have actually been able to do it.
On that path, we’ve needed to build semantic+lexical databases from scratch and massive-scale crawling infrastructure. We’ve rediscovered and then gone beyond retrieval techniques that only Google and Bing used to know.
What’s coming next
We scaled up our training and index infrastructure in the past couple months and are seeing consistent gains in search quality.
We’ll keep scaling up our techniques. In other words, Exa 2.2 is coming soon :)
If you're interested in building one of the largest ML systems in the world, come join the squad!