Search is easy right? Query an inverted index, rank the results, then serve.
- Well what if some users want results in Japanese? Add localization.
- People want both fresh news and timeless references? Add a freshness model that decides what to serve.
- Queries hit a knowledge graph, product index or both? Add a classifier.
- Some customers have specific requirements that don't make sense on every request? In practice, every customer has a unique search path that needs to be accommodated.
Suddenly search isn't so easy: a simple request looks closer to a graph of 20+ node types with many branches.
The challenges are even greater when serving thousands of different AI agents, each with their own needs.
This complexity is increased by the reality that most code is now written by agents: even if agents write locally correct code, reasoning through global constraints and requirements remains hard for them.
Billions of search requests are made on Exa - how do we monitor the decisions made within each request? How do we ensure our search pipelines are robust as most code is written by agents? How do we build observability over a search engine?
To answer those questions, we built CanonaaA canon, in music, is one voice stating a melody and others entering later to overlap and transform it into harmony. A search engine orchestrator is a canon: independent nodes kick off when they're ready, follow the same rules, and combine into one result. - a search pipeline orchestrator that is our solution to ensure full control over our search engine as it scales in complexity.
#Representing search as a DAG
Serving a query in 250ms means running classification, localization, retrieval, and ranking across multiple indexes concurrently. In Canon, we chose to define the search pipeline as a DAG so the executor handles concurrency automatically.
{"nodes": {"dense": {"type": "retrieve","index": "web","numResults": 50},"fetch": {"type": "fetch_content","source": "dense"}},"root": {"node": "fetch","output": "docs","query": "effect-ts fiber runtime evaluation signal","numResults": 10}}"fetch": {"type": "fetch_content","source": "fuse"}},"root": {"node": "fetch","output": "docs","query": "effect-ts fiber runtime evaluation signal","numResults": 10}}
A core value of this is decomposability: every node in the graph can be reasoned about and controlled independently. Swapping a subsystem within ranking or inserting a node between retrieval and ranking is trivial because the graph guarantees the change won't affect anything outside that node's boundary.
#What does a DAG provide?
Automatic Parallelism: The runtime knows the dependencies of each node in the graph, and as a result, it knows the nodes that have no dependencies. All these nodes can be parallelized, optimizing the execution for free.
Durable execution: If a node fails during execution, the runtime can retry from that node without having to execute the nodes before it.
Introspectability: A DAG is data. Data means you can visualize, validate, and analyze it. You don't have to read the code to understand the flow of control.
Definition is decoupled from execution: The Graph describes the flow of data. A separate executor describes how to run it. This allows the same definition to be run synchronously in tests, distributed in production, or in dry-run for previews. Things like caching, retries, tracing live in the executor.
A DAG isn't always the right abstraction. The shape of the work has to match the shape of the abstraction, and a lot of systems aren't shaped like a DAG. It fits when work has dependencies and partial ordering. Reactive event loops violate that because there's no work to schedule, just some state and events that trigger callbacks. Consensus protocols need one exact sequence, and parallelizing operations breaks the guarantees. Feedback loops (for example compiler passes) cycle until they converge to a fixed point, and a DAG can't express a cycle.
#Observability across a search pipeline
A core goal of Canon is to enable visibility across the full search path before a query runs and traceable after it executes, so that anyone at Exa can query this data or inspect it faster.
Previously, our search pipeline was written as a series of sequential function calls, if/else branches, and manual error checks. For example, swapping in a new reranker may require auditing every conditional that might invoke it. Understanding why a query returned bad results might mean debugging logs manually from the new reranker, checking whether any fallbacks fired, etc.
This was particularly painful in the usual ways, cross stack changes touched too many files, concurrency was hand-rolled and inconsistent, errors lost context bubbling up the stack, observability was uneven. None of this is unsolvable in imperative code with enough discipline. But the discipline doesn't hold. The pipeline accumulates inconsistencies because the system gives people too many decisions to make.
It was possible to add logs and figure out where a URL got lost in the search, but reasoning about why it got dropped was like finding a needle in a haystack, a haystack on the order of billions.
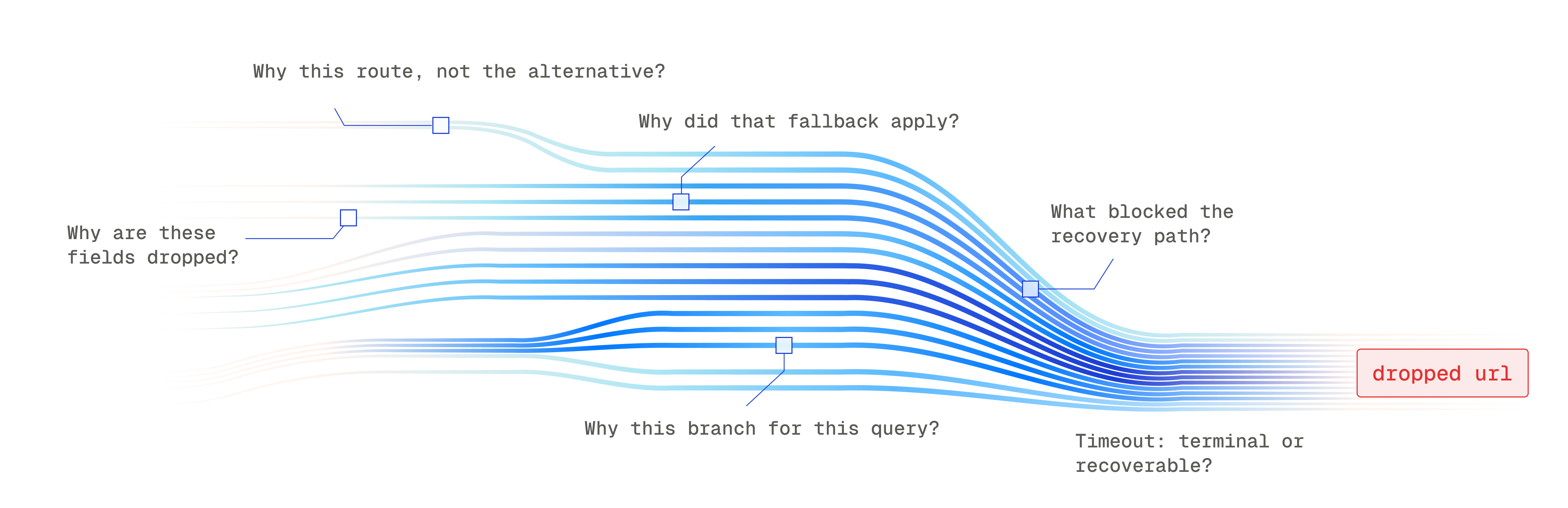
Canon compiles the search pipeline to a serializable graph. When debugging a question like "why did x search query at y date fail to return z url, even if it was the obvious result", Canon allows you to trace the exact path and decisions made by the search engine to figure out which subsystem dropped the URL and why. In addition, when a customer has specific or changing configurations, we can guarantee that the graph matches the search path.
1{2 "query": "how do CRDTs achieve eventual consistency without a coordinator",3 "type": "auto",4 "numResults": 10,5 "contents": {6 "text": true,7 "highlights": true,8 "summary": true9 }10}
Exa's search is only going to get more complex. We are building search across the compute latency spectrum for every agent's needs. Canon gives us detailed tracing for all search paths which enables agents to inspect the graph and identify the root cause of unexpected behaviour in our pipeline before a human even jumps in.
#The Runtime
Canon's runtime was designed to handle orchestration automatically, allowing node authors to focus on business logic of search components independent of the nodes around it.
The graph in Canon describes the search path but doesn't record decisions like cancelled branches or parallelized work since those are properties of the runtime executing it. The runtime evaluates the graph and encodes what to compute in a pull based systembbA node only runs when a downstream consumer asks for its value, as opposed to a push model where every node fires as soon as its inputs are ready. Laziness and cancellation propagation fall out of this for free. - the upstream subtree runs only when the downstream node demands it. The DAG structure allows the runtime to memoize outputs for a node so if there is a diamond dependencyccTwo nodes share an upstream ancestor through different paths, forming a diamond shape in the graph. Without memoization the ancestor would be recomputed once per path; caching its output ensures it runs exactly once per request. the node is not rerun.
This runtime design allows for many of the benefits of Canon:
Maximize compute efficiency: since nodes with no data dependency are executed in parallel, the runtime automatically minimizes total latency. If a parent node is cancelled (time out, client disconnected, lost a race), the runtime cancels every child node, so compute isn't wasted on work nobody needs.
Observability: Since the runtime sits at every invocation boundary, it records timing, inputs, outputs, and decisions automatically and sees everything by default. It enriches any error a node throws with the context of which node failed and what was happening upstream.
All of this works because nodes talk to the runtime through one uniform interface. If a node makes its own network call to a ranking service, the runtime can't cancel it, cache it, or trace it. The node becomes invisible to the system.
Consider a query that races several search indexes, with preprocessing. The web index wins the race, so the runtime cancels all other in flight nodes and their children.
The reranker pulls the retrieval node’s results, runs once, and caches the result. We perform post processing in parallel and return results to the user. The whole request emits a complete trace with zero instrumentation in any node.
Canon enables a clean separation of concerns. Each retrieval node knows how to query its index. The reranker knows how to score documents. Neither node knows about racing, cancellation, caching, or tracing, and neither needs to.
#Agents, Agents, Agents
Everyone is faced with the reality of software engineering in 2026: almost all code is written by coding agents. These agents need a structure that guides them towards correctness and keeps the context of the codebase in mind on the first try. Canon is one such solution.
The stakes of getting this right are high: as the customers we serve are bigger the cost of failure grows, making reliability and fast triage of failure modes more necessary.
Humans navigate sprawling codebases through experience and accumulating intuition over time. Canon makes implicit intuition explicit for agents. Most programmers find that when the code is imperative, duplicated and dependent on a hidden order, the agent is able to learn from patterns in the nearby code to produce code that is both locally and globally valid.
In the old imperative world, correctness lived in hidden branch structure, ordering, and code conventions. Implicit invariants were everywhere:
- Were the contents already fetched?
- Do we have content to rerank?
- Did we handle moderation?
Canon treats retrieval orchestration as a typed execution graph, turning those assumptions into explicit constructs. The agent spends less effort reconstructing unwritten rules and more effort checking whether the graph it produced is correct. The burden of correctness is carried by the type systemddTypestate: a type-system technique where types encode an object's current state alongside its shape, so operations illegal in that state become compile errors instead of runtime bugs., the graph schema, and the runtime, not by the context window of the agent.
The runtime also eliminates entire failure domains through totalityeeA total function is defined for every input in its domain. Canon extends this to graphs: every node must handle every outcome it can produce, and the type checker rejects any graph with a missing branch.: Canon graphs specify what happens for every outcome of every node, so you can't ship a graph with unhandled outcomes.
#Conclusion
Exa's search is only going to get more complex, as we offer more search types or there are a growing number of customers that require increasingly specific search paths. Canon is a search orchestrator that is our solution to build observability and monitoring across these pipelines.
The graph makes the search path explicit. The runtime runs it: parallelizing independent nodes, cancelling work nobody needs, memoizing outputs across diamond dependencies, and recording a complete trace at every invocation boundary. The burden of correctness is carried by the schema and the runtime. Building a search engine requires us to build systems that ensure quality and correctness at a massive scale.