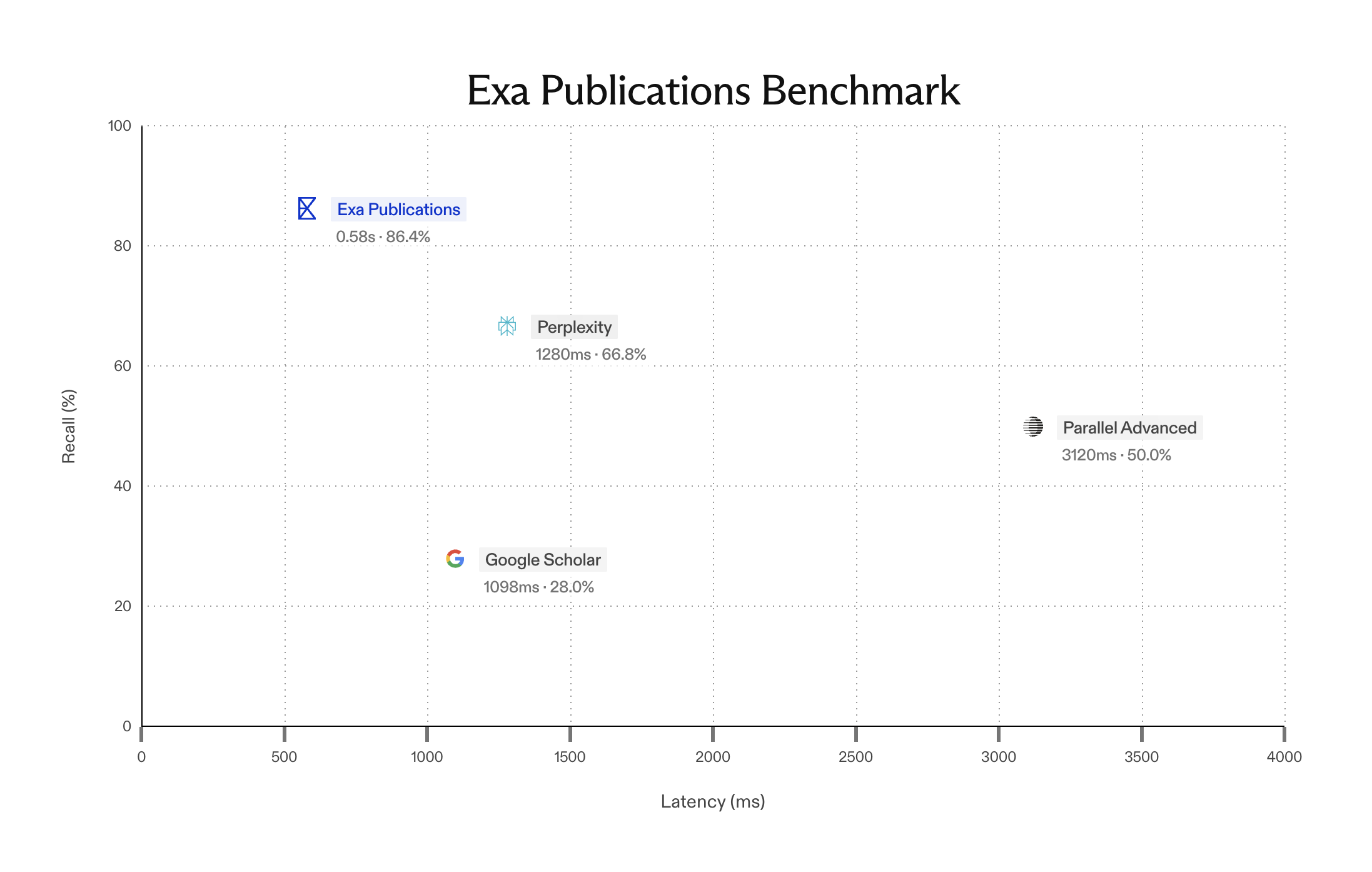
Introducing Exa's Company Search Benchmarks
Introducing Exa's Company Search Benchmarks
Company search spans categories like geographic filters, funding data, and company size, driving workflows from sales to supply chain procurement.
Similar to our people search benchmark, we fine-tuned our retrieval model for company search and built an ingestion pipeline optimized for entity matching. To measure progress, we created an ~800 query benchmark and open-sourced the evaluation harness.
How People Use Company Search
Company search covers everything from verifying a specific entity to discovering all companies that match a filter set. Quality depends on index freshness and how well the system extracts structured attributes.
- "Tell me about exa.ai"
- "Agtech companies optimizing pesticide placement with computer vision"
- "Law firms that specialize in patent law"
- "Companies like Bell Labs"
- "Car companies that sell sedans under $50k"
- "Japanese AI companies founded in 2023"
- "Wi-Fi companies that are not Verizon"
- "Clinical trial sites specializing in oncology"
- "Luxury home design companies in New Jersey"
How We Evaluated
Existing benchmarks test queries about Stripe, Notion, and Figma. LLMs already know these companies from pre-training, so high scores conflate memorization with search capability. We wanted queries that require actual retrieval.
Building an LLM-Hard Dataset
This dataset includes relevant attributes for company search such as founding year, location, industry, employee counts, and funding history. To ensure retrieval vs memory, we deliberately avoided well-known unicorns:
| Include | Avoid |
|---|---|
| Series A/B companies | Stripe, Revolut, Klarna |
| Companies with <500 employees | Notion, Figma, Canva |
| Regional players (EU, APAC, LATAM) | US-dominant global brands |
| Niche B2B verticals | Consumer tech darlings |
The result: YC startups from W20 through S24, European tech across fintech and industrial IoT, APAC companies in Japan and Singapore, and verticals like cybersecurity, logistics, and simulation software.
Static vs Dynamic Facts
Static facts (founding year, HQ location) vs dynamic facts (employee count, funding totals) require different evaluation approaches. Static facts have stable ground truth; dynamic facts need temporal anchoring or tolerance windows.
The benchmark splits between static facts that get exact-match scoring and dynamic facts. We'll plan to add a refresh interval to ensure temporal drift is not significant.
Retrieval Track
The retrieval track tests whether systems return the right companies for a given query. 605 queries across five types:
| Type | Example |
|---|---|
| Named lookup | "Sakana AI company" |
| Attribute filtering | Industry, geography, founding year, employee count |
| Funding queries | Stage, amount raised, recent rounds |
| Composite | Multiple constraints: "Israeli security companies founded after 2015" |
| Semantic | Natural language descriptions of company characteristics |
We have a series of representative code examples below:
For attribute filtering (industry + geography):
{
"query": "fintech companies in Switzerland",
"constraints": {
"hq_country": {"eq": "Switzerland"},
"categories": {"contains": "fintech"}
}
}For dynamic attributes like employee count:
{
"query": "cybersecurity companies with over 200 employees",
"constraints": {
"employee_count": {"gte": 200},
"industry": {"contains": "Security"}
}
}For composite queries with multiple constraints:
{
"query": "Japanese AI companies founded in 2023",
"constraints": {
"hq_country": {"eq": "Japan"},
"categories": {"contains": "ai"},
"founded_year": {"eq": 2023}
}
}RAG Track
The RAG track tests whether systems extract correct facts from retrieved content. Our company search includes 201 queries across static and dynamic attributes for this:
| Query Type | Example | Expected |
|---|---|---|
| Founding year | "When was [Company] founded?" | "2019" |
| Employee count | "How many people work at [Company]?" | "86" |
| Last funding | "When did [Company] raise their last round?" | "November 2024" |
| YC batch | "What YC batch was [Company] in?" | "S24" |
| Founders | "Who founded [Company]?" | "Alice Chen, Bob Park" |
| Multi-hop | "What is the legal name of the company founded by [Person]?" | "[Legal Entity Name]" |
| Verification | "Has [Company] raised over $500M?" | "No" |
Conclusions
Our Company Search Benchmark joins our People Search Benchmark as part of a growing suite of public evals. We're open-sourcing the dataset and harness so it can serve as a benchmark others can run and use to push retrieval research forward.
For this benchmark, we focused on the gap between how LLMs answer company queries (from memorized knowledge) and how retrieval systems should (from fresh, structured data). The evaluation tracks cover both retrieval and fact extraction, with explicit handling for static vs dynamic attributes.
Company search is one vertical. The broader goal is to build an evaluation ecosystem across entity types and search domains, pushing retrieval research forward in service of Exa's mission of building perfect search.
Try it
- Benchmark repo
- API Playground (category = "company", type = "auto")
- Exa.ai
Questions? hello@exa.ai