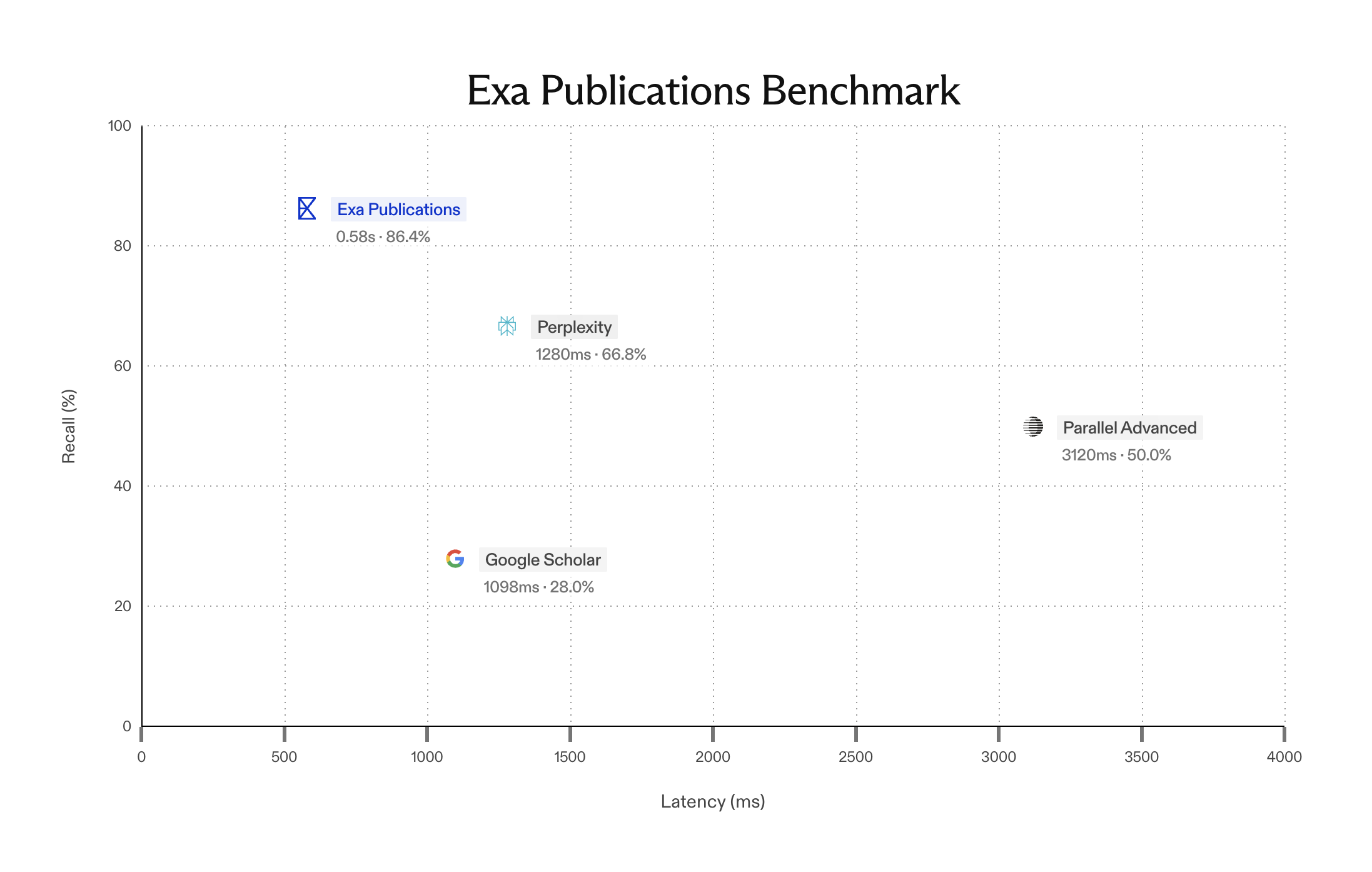
Serving BM25 with 50% memory reduction using a novel encoding scheme

Introduction
Today, I'm excited to share how we optimized our BM25 index by more than 50% across billions of documents, without any drop in performance.
At Exa, our mission is to organize the web to handle complex queries. Traditional keyword search techniques like BM25 are crucial to that mission.
While Exa has developed novel embedding-based approaches to understand semantics beyond keywords, the most powerful search architecture is a hybrid approach that combines both keyword and embedding methods.
Our 50% optimization on our BM25 index means we can now serve many more documents at the same price point — which means a better search experience.
In this post, we'll dive deep into the high-level algorithms and low-level memory structures we used to squeeze as much juice as possible from the hardware.
General Approach: Efficient BM25 Implementation at Scale
BM25 is a common retrieval algorithm that balances term frequency, document length, and term rarity. To implement this at billions-document scale, we optimized our system on 2 orthogonal dimensions: a smart adaptive query algorithm and an efficient in-memory data structure.
Smart Candidate Selection & Dynamic Pruning
- Selective initial retrieval: We identify the rarest query terms (highest IDF scores) and use their postings lists to create a targeted candidate set—a form of "impact-ordered indices" approach.
- Threshold-based pruning: During score calculation, we dynamically eliminate documents that mathematically cannot reach the top results—inspired by the WAND top-k retrieval algorithm.
This two-pronged approach dramatically reduces computation by:
- Starts with only the most promising candidates
- Abandons unpromising calculations early
- Directs computational resources where they matter most
The result is a retrieval system that efficiently identifies the best documents from billions of candidates while maintaining sub-500ms latencies to retrieve 1000s of top results.
Memory as the Limiting Factor: Every Bit Matters
While our algorithm is optimized for query time performance, we faced a critical scaling challenge: memory overhead. The retrieval algorithm relies on an in-memory inverted list data structure (BM25 index), covering each unique token and their frequencies in every document.
As our index grew to many billions of documents, the memory overhead of our BM25 index became expensive: over 1.8TB per 1 billion indexed documents across distributed workers, making a nice dent in our monthly AWS bill. So, what can we do to reduce the memory overhead of the BM25 index, while maintaining its inverted list logical structure that enables fast query performance?
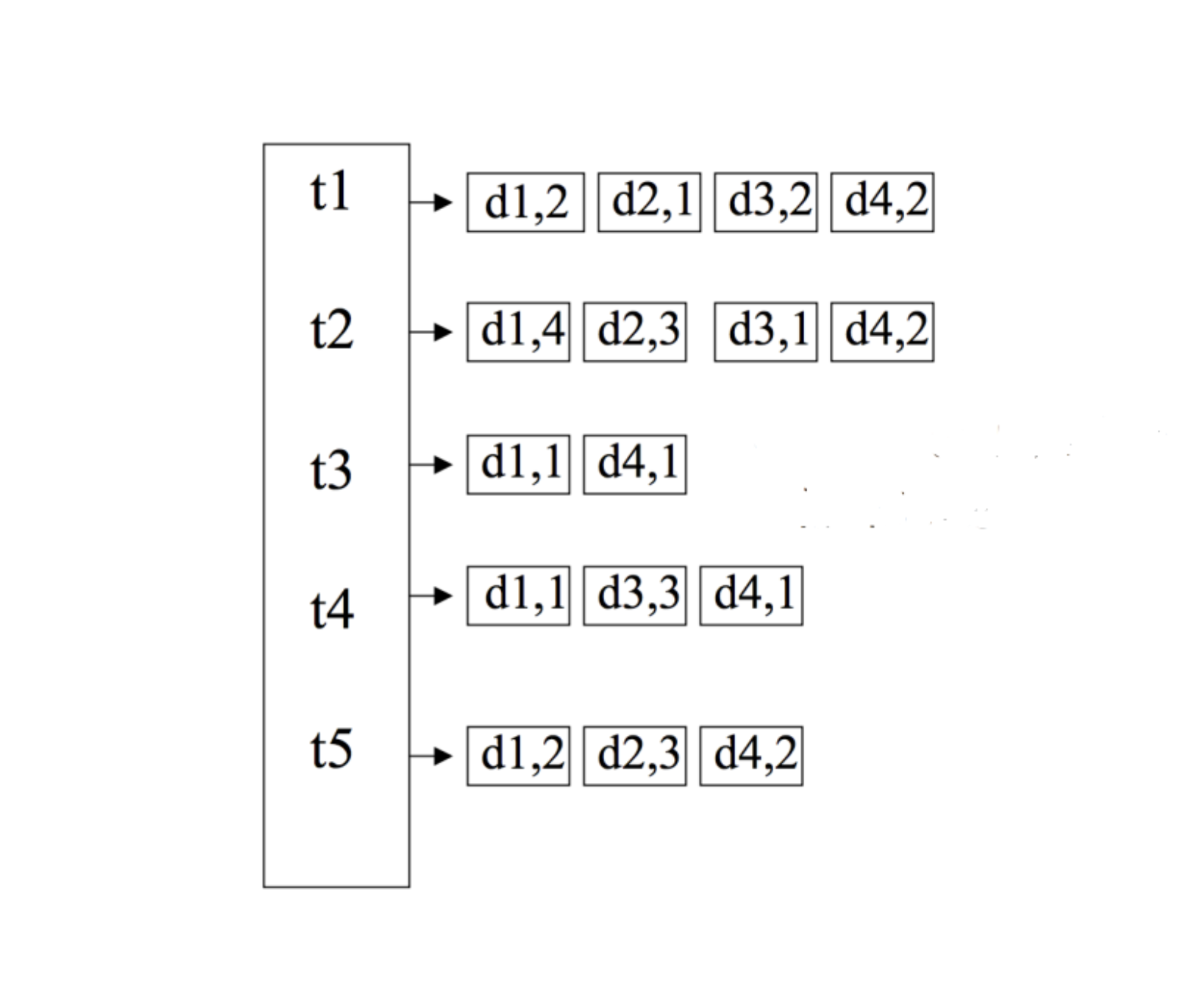
The in-memory Representation
The inverted index structure we optimized
The inverted index is a well-known data structure, where each unique token has an associated postings list containing (document id, token frequency), sorted in ascending order by doc_id. Typically, we use a hashmap to represent the overall index, with token_id as keys and a vector of (doc_id, freq_count) tuples as values. While this approach provided the fast random access we needed for query processing, it had several inefficiencies that became problematic at scale:
- Vec allocation: Each postings list required its own separate memory allocation with associated overhead
- Uncompressed document IDs: Document IDs were stored as fixed-width 32-bit integers, despite many having much smaller values
- Structure padding: Even with packed data representation in Rust, there were memory alignment inefficiencies when constructing the tuple list
- Redundant frequency storage: Token frequencies (typically in the 1-15 range) were stored repeatedly for each document
When operating at our scale, even a single bit saved per posting translates to significant memory savings. This realization led us to our optimization mantra: every bit matters.
Key Optimization Techniques
To address these inefficiencies, we implemented several targeted optimizations that builds on top of each other:
1. Frequency-Based Organization
Instead of storing each (doc_id, freq) pair individually, we group documents by their term frequency:
// BEFORE
[(doc1, 1), (doc2, 3), (doc3, 1), (doc4, 3), (doc5, 2) ...]
// AFTER
[(1, [doc1, doc3,...]), (2, [doc5,...]), (3, [doc2, doc4,...])]This leverages the observation that token frequencies typically fall within a small range (1-15), and much higher frequency values provide little help improving the search quality. By grouping documents with the same frequency, we only need to store the frequency value once per group rather than for each document, significantly reducing redundancy.
2. Variable-length + Delta Encoding for Document IDs
Great, now we removed a big chunk of redundancy, but each freq that we just removed was only a single byte. Assuming the (doc_id -- 4 bytes, freq -- 1 byte) pairs are the only data we store in the BM25 index, this is only a max 20% reduction in the best case scenario. Hmm, we can definitely do more, why use 4 bytes for doc_id? Does it really need all that much? Absolutely not! Since document IDs in a postings list are always sorted, we can store much smaller numbers if we only store the deltas, and smaller numbers translate to fewer bytes.
Furthermore, who says we need fixed bits data representation? Why use 2 bytes to represent the number 255 when a single byte suffice? Combining delta + variable based encoding, we just reduced the average overhead from 4 bytes to 1.3 bytes to encode a single doc_id, how about that?
// BEFORE
[(1, [doc1, doc3,...]), (2, [doc5,...]), (3, [doc2, doc4,...])]
// AFTER
[(1, [variable-delta encoded bytes buffer]), (2, [variable-delta encoded bytes buffer]), (3, [variable-delta encoded bytes buffer])]3. Zstd compression (cuz why not?)
Our query algorithm always accesses the postings list, never parts of it, so the entire list needs to be scanned and decompressed when requested at query time. We handle this access pattern well, because all of our encoding/compression techniques so far are perfectly streamable: producing decoded (doc_id, freq) pairs on the fly. This makes it ideal to integrate zstd on top of our custom encoding scheme for our very large postings list, since zstd is built for fast, lossless, streaming compression/decompression with good compression ratio, thus reliably reducing memory overhead with minimal added latency.
4. Consolidated Buffers
At this point, we've reduced our logical data overhead by quite a bit, but have ignored the hidden costs and overheads: data structure metadata, tuple representation alignment, fragmented malloc requests etc. These overheads quickly add up for short/medium length postings lists. At minimum, for each "inner list", we need 1 byte for the frequency value and 24 bytes for the inner Vec Rust data structure.
Solution: flatten all the inner lists and use a single Vec to represent everything! We just need to know what distinct frequency values the flat list contains, and the boundaries of each inner list, something like this:
// BEFORE
[(1, [encoded_range_1]), (2, [encoded_range_2]), (3, [encoded_range_3])]
// AFTER
data buffer: [encoded_range_1, SEPERATOR, encoded_range_2, SEPARATOR, encoded_range_3]
unique_freq_values: [1, 2, 3]This requires us to use a separate unique_freq_values structure, and a special, reservedSEPARATOR token in the data buffer. Remember how we only use distinct frequency values between 1 to 15? This means we only need 2 bytes bitmap to represent unique_freq_values. Furthermore, since theencoded_range contains sorted, unique doc_ids, and we encode the delta with var len encoding, this means only doc_id of 0 can be encoded as a zero byte. We can use a simple doc_id + 1 transformation before encoding, so that no encoded_range bytes can be zero, making it the perfect single byte SEPARATOR. The final result is a highly compact bytes buffer with minimal overhead. A small postings list containing 100 doc_ids and 15 distinct frequency values only incurs a 16 bytes overhead: fixed 2 bytes for the bitset, and 14 bytes for the separator tokens.
[2_BYTES_BITSET_HEADER, encoded_range_1, ZERO, encoded_range_2, ZERO, encoded_range_3,...]5. Singleton Optimization
Up to this point, our simple but effective techniques work well for popular tokens with medium/long postings list, but the real index follows a power law distribution with lots of unique tokens that only appears once, in a single document. Encoding these in a consistent format as the long postings list means a 16 bytes metadata overhead for the outer Vec, a 4 bytes overhead for the frequency value of 1, another 16 bytes metadata overhead for the inner Vec associated with frequency of 1, and alignment padding overhead for the tuple. This is unacceptable overhead for just a single doc_id, so we made a special case for these "singleton" tokens.
// BEFORE: Full postings list structure
[(1, [doc_id])]
// AFTER: Just a single number
doc_id6. Consolidated Buffers 2.0
Even with the most compressed data representation for each postings list, it still requires a 24 bytes overhead to allocate the Vec data structure in Rust: 8 bytes for size, 8 bytes for capacity, and 8 bytes for the address of the underlying heap allocated memory, not to mention the repeated, small malloc requests (yes, underneath the hood, Rust still uses malloc) for each postings list can cause internal fragmentation and memory allocator pressure. Since we already consolidated once, we might as well go all the way.
Instead of 1 Vec per postings list, we use a single, continuous Vec that holds all the compressed postings list, for all unique token_ids. Then, the original token_id → postings list hash map entry can just contain a (offset, len) pointer into the big Vec. Thus reducing the original 24 bytes overhead per token down to 8 bytes (two 32bit integers in each pointer).
// BEFORE: Separate memory allocations
token1 → [compressed_postings...]
token2 → [compressed_postings...]
// AFTER: Consolidated buffer
buf: [token1_postings,...token2_postings,...]
token1 → (offset=0, length=X)
token2 → (offset=X, length=Y)Query Performance Impact
While our primary goal was memory optimization, we were careful to monitor query performance impacts, and observed a surprising result: average query latency dropped by 10%! We believe this is due to the compressed, centralized postings list data leads to much more predictable, repeated memory access patterns, reading fewer bytes overall, which is quite cache/CPU friendly!
Whats next
This optimization isn't just a technical achievement—it's a foundational improvement that enhances our entire search infrastructure:
- Greater retrieval capacity: We can now retrieve from a larger candidate pool during BM25 retrieval
- Lower operational costs: Reduced memory consumption means lower infrastructure costs or the ability to index more documents with the same resources
- Faster cold starts: Smaller memory footprint means faster loading times when instances start up or scale
- Better hybrid search quality: By improving the initial retrieval stage, we enhance the overall quality of our hybrid search results
These optimizations illustrate a fundamental principle in large-scale systems: when operating at billions of documents, every bit matters. Even a small improvement in how we represent information can lead to large system-wide benefits.
These optimizations also bring us one step closer to our goal of making internet search feel like you're being personally guided through the grand total of human knowledge – a mission that requires both the precision of keyword search and the intuition of neural models working in harmony.