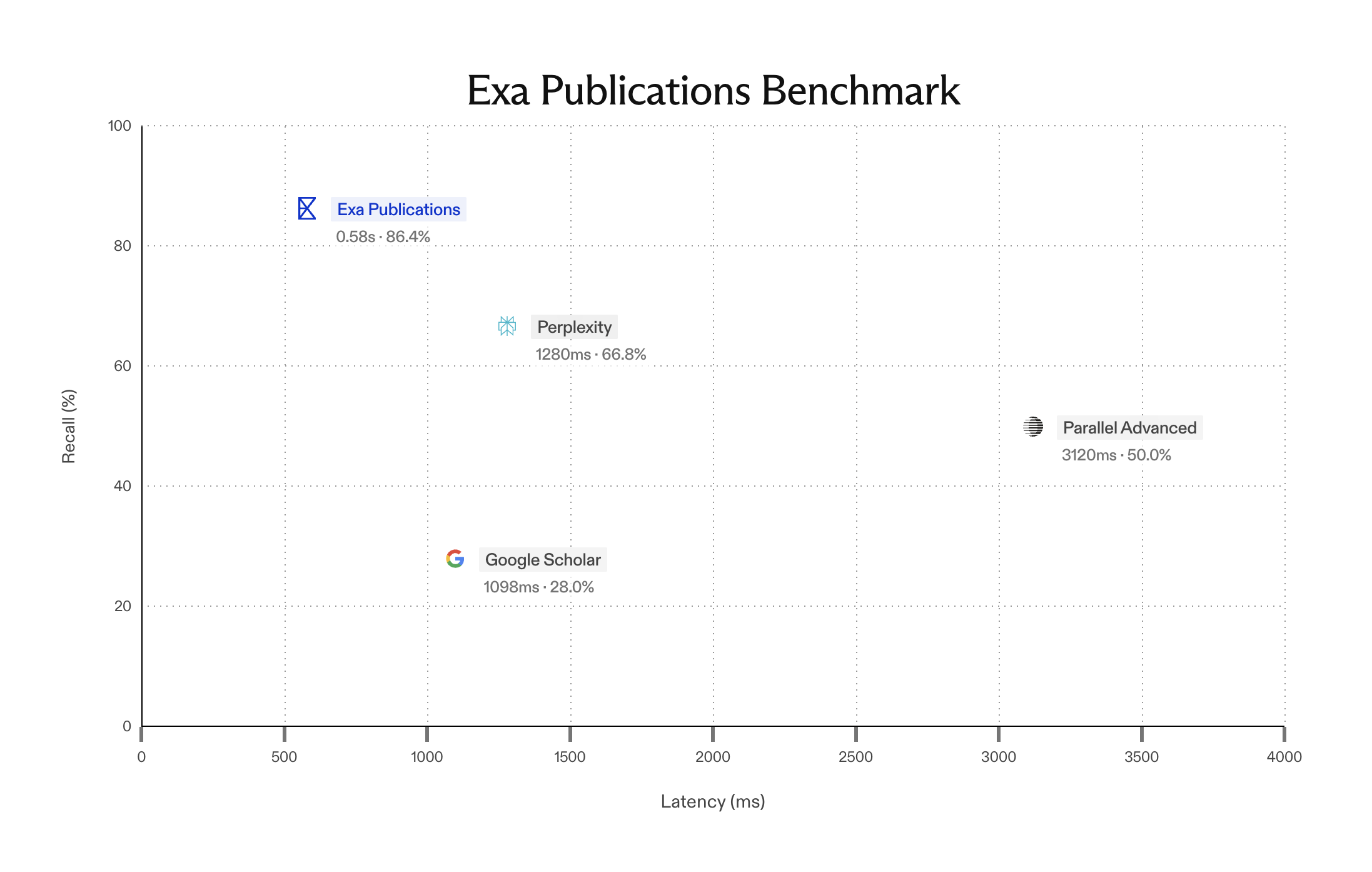
How we're building the next generation of search

Web search is still in the dark ages
There's been a ton of recent buzz about search (today included!) but there still does not exist a tool to perfectly find information.
We started Exa to build perfect web search. In this post, I'll explain at a high level how we're building this end-to-end.
The requirements
A perfect search tool needs to:
- understand arbitrarily complex queries ("engineers in SF who know design and who have a blog but who haven't...")
- return any response type ("find every single matching result on the web and give summary of each")
- expose full control and personalization ("filter to only articles that match these stated preferences")
- scale compute per search as needed ("use 100x more compute to solve this search")
Traditional search engines like Google can't do this -- they were built in an older era to handle simpler queries like "homepage of costco" or "taylor swift boyfriend".
Exa is a next-gen search engine, built to power the AI world's ever increasingly complex informational needs. To build it, we're redesigning the whole system from the ground up.
The fundamental infrastructure
Web search always involves three fundamental pieces: crawling documents, preprocessing the documents for retrieval, and serving queries.
The first step is gathering the data. Not an easy task -- the number of documents on the web is massive (many petabyes), the documents have wildly different formats, and the documents are constantly changing.
To build Exa's crawling system, we constantly look for new urls, crawl them across a distributed network of machines and IPs, run documents through a custom-built html parser, and store in s3. Most of the documents are low-quality though, and a difficult challenge is identifying the best urls to ensure a high quality index.
After gathering billions of documents, the second step is preprocessing the documents for retrieval. Here is where the secret sauce comes from. Unlike other search engines that preprocess documents into keywords, we train neural models to preprocess each document into embeddings. More on that in the next section.
Now that we have our expanding index of documents and embeddings, we need to serve this to users. Our goal was a low cost system that could serve many queries per second and also enable a variable amount of compute per query. That required building our own vector database and optimizing everything from the high-level clustering algorithm to the low-level assembly operations.
For each of these systems, the devil is in the details. Crawlers will be blocked, queries have near infinite variety, and custom databases are tricky. Above all, the scale of data involved here is so large that any sort of operation, even updating one piece of metadata, requires immense amount of compute and therefore thoughtfulness, planning, and grit.

A neural search algorithm
Foundational to Exa is a belief in the "Bitter Lesson". The Bitter Lesson is an essay by computer scientist Richard Sutton arguing that over the history of computers and software, the systems that leverage computation outcompete those that do not.
Deepmind believed in the Bitter Lesson when they built AlphaGo, which played itself millions of times. OpenAI believed in the Bitter Lesson when they scaled up GPT-4, Sora, o3 and everything in between. In each of these cases, the system that was able to absorb more and more compute to get better and better results was the one that succeeded.
Google search does not believe in the Bitter Lesson. Google's retrieval algorithm mainly uses keywords -- it compares the keywords in the query to the keywords in each document on the web. While this is very cheap, efficient, and works fine in many cases, it does not leverage compute. Meaning, you can't throw more compute at a keyword algorithm to make it better. It's static. This is the fundamental reason why Google search hasn't really changed much in years, while the rest of the AI world has achieved miracles. (To be clear, LLM summaries have definitely changed the search experience, but the underlying search engine hasn't changed much.)
Exa is only interested in search algorithms that can leverage more compute to get better. We currently use an embedding-based algorithm to do that. We train specialized transformer models to process each document into an embedding or set of embeddings. An embedding is just a fancy way of saying a list of numbers. This list of numbers is strictly more powerful than keywords because it can capture deep information about a document. Mixed into this humble list of numbers lies every argument in the document, every style choice, even all the keywords. Pretty wild.
Crucially, embedding models can leverage compute. The more we train them, the better they get. Though off the shelf embedding models exist, web-scale search is a unique beast that requires specialized and highly precise embedding models. That means we need a ton of data and a ton of GPUs.
On the data side, we've developed novel methods for gathering embedding training data from the web for high precision web search. Our search just keeps getting better the more of this data we train on.
And on the GPU side, we set up a pretty substantial cluster of 144 H200s GPUs (in a datacenter and thankfully not in our office!). Because it's 18 nodes of 8 each, and Exa means 10^18, we refer to it lovingly as our Exacluster :)
The Exacluster is a testament to our belief in the Bitter Lesson.

Two products, one mission
As a search product aiming to reach perfect search, we need to provide our users with highly customizable search that fulfills all their particular web information needs.
Unlike traditional search engines that have one search experience for all consumers -- everyone gets the same Google -- we serve businesses, and every business has different search needs. Some businesses need super low latency, some need specialized moderation, some need 1000s of results, and so on. Exa search is designed to be configurable, so that everyone gets the version that's personalized to them.
Perhaps the most interesting axis that differentiates customers is the time they're willing to wait for a search. Searches come in many shapes and sizes and some are far more difficult than others. While simple searches like "homepage of costco" can be solved in half a second, other searches like "find every company in this sector that raised a series A" might need several minutes of computation.
That's why we've built two different products -- Exa Search and Exa Websets. Exa Search is a general search API that returns quickly and satisfies most searches. Exa Websets is a product that's meant for the hardest of queries, the ones you're ok waiting minutes for to get a perfect list of results.
In the OpenAI analogy, Exa Search is our base model like GPT-4, and Exa Websets is our test-time compute model like o3. We'll have an API for both, and one day, these will be merged. Our GPT-5 search model is in the works.
While the large labs race to train the next generation of LLMs, we're the only lab -- to our knowledge -- training the next generation of search. What they want to do for intelligence we want to do for knowledge. Perfect search is our AGI -- fantastical sounding at first, world changing on second thought, and only a couple years away.
As we build toward perfect search, we're proud that our mission firmly aligns with our product incentives. Give our customers and the whole world full control to find whatever information they need, and we all benefit.