How we do evals at Exa

Evaluating the Best Search Engine
At Exa, we've built our own search engine from the ground up. We developed a distributed crawling/parsing system, trained custom embedding and reranking models, designed a new vector database -- all in order to build the best search engine to serve AI applications.
When we evaluate Exa search on a variety of benchmarks, we consistently perform state of the art compared to other search APIs. Using Exa retrieval in your application should improve performance on downstream tasks.
But what does "best" actually mean? How do you evaluate web search quality? In this post, we'll share both our evaluation results and our philosophy behind evaluating web search.
Our Evaluation Results
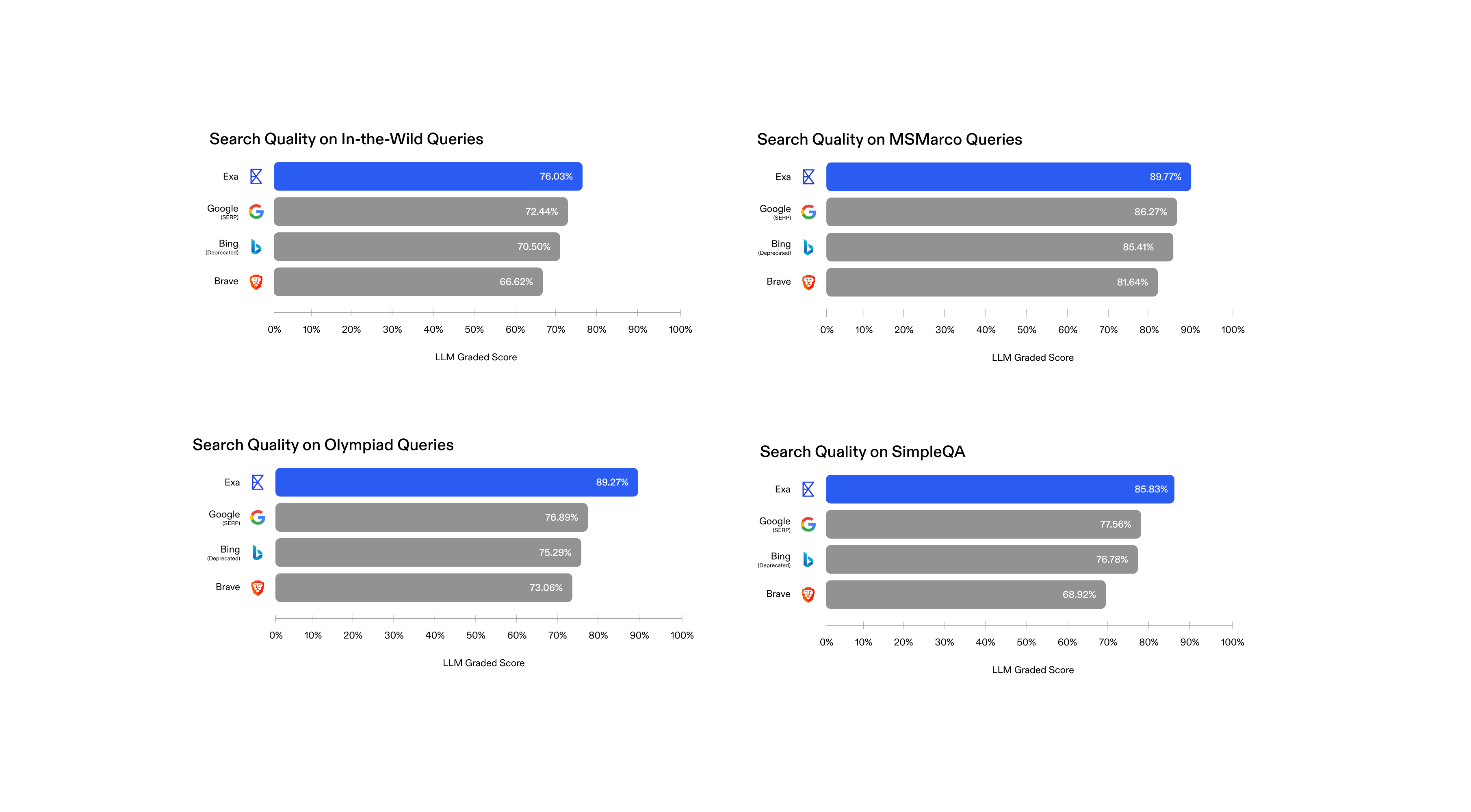
Pure Result Grading
We can evaluate search result quality by having LLM graders score the relevance and quality of results returned for different query sets. We run queries through each search engine, then pass each (query, result) pair to an LLM grader, which independently evaluates the relevance and quality of the result for the query, outputting a score between 0 and 1. The final score is the average across all queries and results.
We test on three result grading datasets:
- In-the-wild queries: 5,000 real de-identified queries from Exa
- MS Marco Queries: 10,000 queries from the MS Marco dataset
- Exa Olympiad: ~500 challenging queries we hand-crafted to test reasoning and deep knowledge
The results show Exa (dark blue) performing the best across each query set. Notably, our advantage is most pronounced on the challenging Olympiad dataset, because complex queries require semantic understanding where our architecture excels.
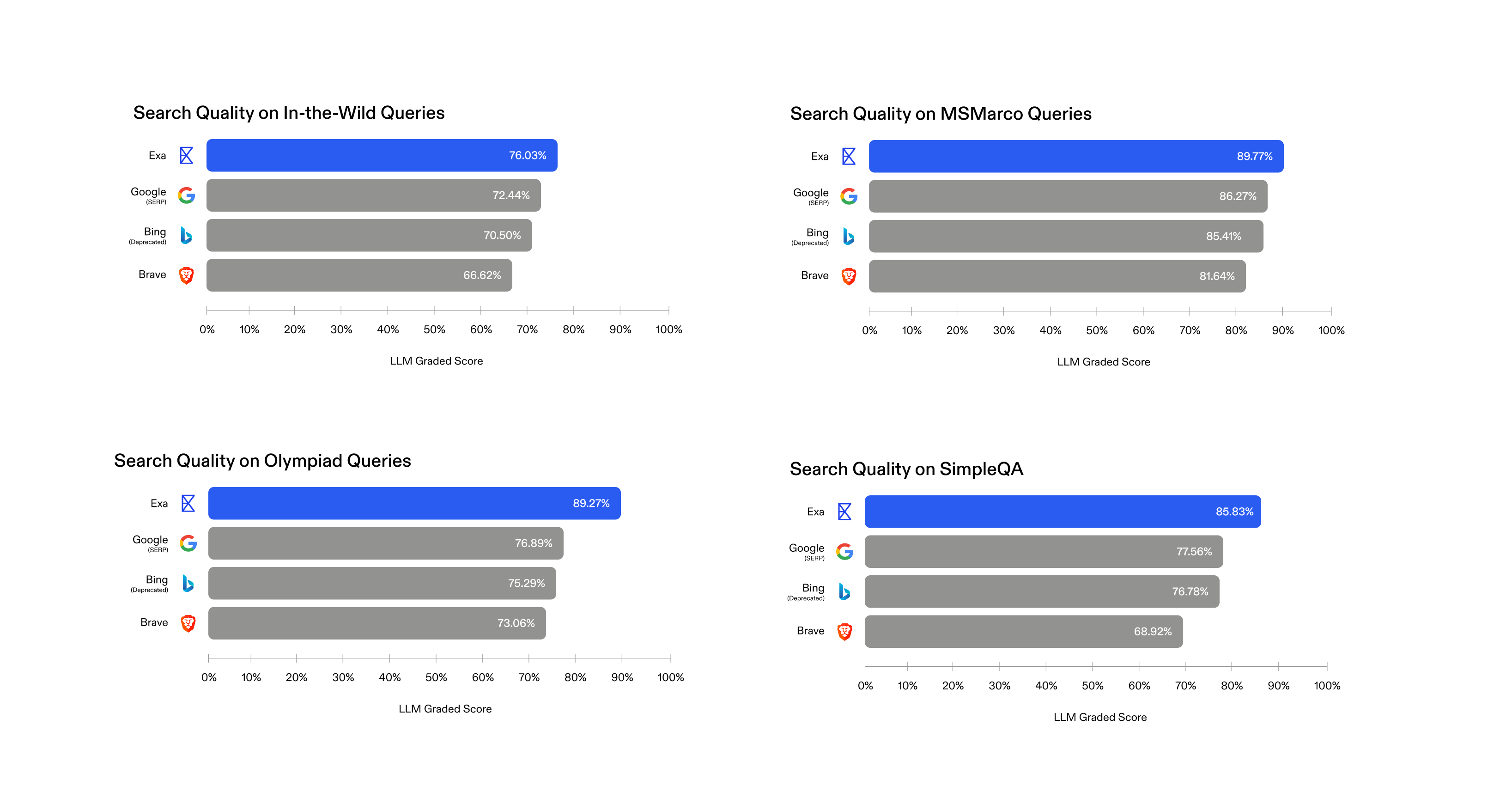
RAG Grading
We can also evaluate search quality by how much it enhances LLM question-answering. We can use SimpleQA, where an LLM agent must answer factual questions using search results.
We pass each question to an LLM, which calls the given search engine multiple times in a loop until it outputs the final answer. We then grade whether the LLM correctly outputs the expected answer using another LLM with the SimpleQA grader prompt provided by OpenAI. The score is the fraction of questions correctly answered by the LLM + search agent.
Here, Exa achieves the highest performance, meaning our full search allows LLMs to produce more factually grounded RAG outputs. (Note, we chose a simple prompt to minimize bias across search engines, so this is not our SoTA simpleQA score)
Our Evaluation Philosophy
Now we'll take a step back to explore how we approach search evals from first principles.
What Good Evaluations Should Measure
Fundamentally, we believe an evaluation of retrieval should actually incorporate downstream tasks based on that retrieval. This might look like:
- Providing a coding agent with retrieval over docs so it can use libraries and debug errors from the web
- Enabling a chatbot to retrieve over the web to answer questions about real-time events in the world, or answer long-tail questions that require information not available in the LLM weights
- Finding related papers to help explore a new research agenda
- Determining the right product to buy
- Sourcing good candidates to hire
The platonic ideal of an evaluation is simple—test how well the system accomplishes that downstream task with different retrieval systems, or with no retrieval at all. If the task is well defined enough, and the system modular enough, this is the north star—it answers exactly how well the retrieval system performs.
However, we've found that pinning down accuracy on downstream tasks is often hard, expensive, or intractable. In some domains, like coding agents, it's possible to define a (somewhat) objective ground truth, like SWE-Bench. In others, like using retrieval in a general chatbot system, any evaluation of the quality of the answers is necessarily imperfect or limited. Any answer to evaluating search engines that reduces to evaluating LLM output is bottlenecked by our ability to evaluate LLM output—and the perpetual debate on LLM evals shows us how limiting that bottleneck is.
Even when we can define a good downstream objective to evaluate, there are still practical reasons why this only provides a limited picture. Performance with retrieval on a downstream task gives a scalar value for how well the system as a whole uses retrieval, but it can't answer many of the fine-grained questions we need to actually iterate on a retrieval system.
Suppose a coding agent has access to two different search tools, and we find that the agent with search A does 3 percentage points better on SWE-Bench than the agent with search B. Great! It seems we should use search A.
But using search isn't just a binary choice—this number obscures important questions that are deeply relevant if we want to continue to improve:
- Is the coding agent calling search enough, or at the right time?
- Are the queries the agent issues well tailored for the search engines?
- Are the webpages returned by the search engine relevant to the queries it asks?
- Does the page content returned by the search engine contain the chunks of information necessary, or is the scraping/chunking the bottleneck?
- What categories of query does each search engine do well at—perhaps we should use both in concert?
These questions are important for us to answer, to determine how to improve our search, but they're also necessary for understanding what makes search valuable.
For these two reasons—evaluating downstream tasks is often hard or infeasible, and scalar scores on downstream tasks don't provide granular enough feedback to iterate—we've found it necessary to evaluate retrieval beyond how it performs as part of a larger system.
MS Marco Myopia
In the rich information retrieval literature, retrieval is traditionally evaluated by what we'll call"closed evals". MS Marco is a representative example.
MS Marco consists of three components:
- A query set of 1 million Bing user queries
- A fixed document corpus of 3.2 million passage snippets
- Binary human labels for each query, indicating which passage is relevant
Retrieval systems are evaluated on MS Marco by retrieving the top passages for each query, and reporting metrics like MRR: over all queries, what is the average position in the retrieved results of the first document marked by the human labelers as relevant.
While MS Marco is now retired for new submissions, its structure is representative of many similar closed datasets. Other common closed evals include BEIR (the retrieval subset) or Trivia QA.
Closed evals have some important benefits. By holding the index and grades constant, you're able to compare different retrieval methods (like BM25 or embedding models) in a reproducible way.
False Negatives
Scores on MS Marco are determined by how often your model output agrees with the human labelers' choice of the most relevant document. However, as we've seen, and as Arabzadeh et al. noted, these scores have many false negatives. Often, the top documents a model returns are listed as irrelevant, but both human and LLM judges rate those documents as higher relevance than the top document as labeled by humans.
This is not saying that MS Marco has bad human labelers. Fundamentally, for a corpus of millions of documents, it is infeasible for humans (and even LLMs) to accurately label each document for each query—that relevance matrix would be 1 million × 3.2 million = 3.2 trillion labels.
Instead, labels must be sparse. Typically closed evals are constructed by approximately retrieving candidate documents, and having humans select the top document from that. But this is upper bounded then by the quality of the initial approximate retrieval—if a true positive was never even shown to the human labelers, it will be labeled as a negative, regardless whether the human labelers would've selected it.
Scale Matters
One way to solve this false negative problem is to reduce the corpus size. Many closed evals are like this, including MS Marco Passage Ranking. Instead of a shared corpus of millions of documents, each query has a small (~50) independent corpus of documents, again labeled positive or negative for that query.
This makes it much more feasible to avoid false negatives, because humans can feasibly grade every document for each query. As always, it is still possible for the labels to be wrong, but the small scale makes this much less likely.
However, this comes with a steep price. Our goal is to see how often the model can pick the correct document out of ~50 documents, and use that as a proxy for what we actually care about, which is how often the model will select the platonic correct document out of a web-sized index, of billions of documents. But at Exa we've seen in practice that this is an imperfect proxy: performance at small scales doesn't necessarily hold at large scale.
Reimers et al. investigate this as well, showing theoretically and empirically that dense embedding model performance decreases faster than sparse models' with respect to index size. We've seen this not only in comparing dense vs sparse models, but also even within different models. This is also an artifact of how embedding models are trained—in training, the effective corpus size is determined by the batch size, which is typically much smaller than the production corpus size. We've done a lot of research at Exa into mitigating this, but the problem still remains—better retrieval over 3.2 million documents might not be better over billions.
Closed Evals Need White-Box Access
By definition, closed evals require controlling which documents you retrieve over. A positive label for a document for a given query does not mean that this is the theoretically optimal document, merely that it is the best document of the documents in the corpus.
But when picking a general web search API, you don't have control over which documents you retrieve over. Instead, the search provider retrieves over all documents in their index, which is certainly larger than the 3.2 million MS Marco corpus, and may not even contain all documents in the corpus.
Thus, even ignoring the within-corpus false negative problem from above, a metric like MRR doesn't make sense when retrieving from a general web search API. If the labeled positive document appears in position 10, the 9 above may in fact be better than the MS MARCO labeled positive. The labels, by definition, can't tell you about documents not in the labels, and naively using MRR may simply be penalizing a web search API for having a larger, and better index.
MS Marco Is Not the Distribution We Care About
A good eval should answer the question: on the queries we care about, how well does a retriever perform. But MS Marco (or any closed eval) is likely not the exact distribution of queries that are relevant for our use cases. They're taken from users' Bing searches, from before 2020. If we're interested in evaluating performance on recent searches, or different languages, or multiple clause complex queries, or about specific domains like coding, those types of queries are certainly underrepresented in the distribution, and may not even be present at all.
Indeed, we've found it's often quite tractable to obtain more relevant queries. When we have an existing system, there's no substitute for simply sampling from actual queries. Even when that's not feasible, writing a representative set of ~100 search queries can easily be done in a couple hours—we do this often at Exa.
However, the challenge with closed datasets is that while obtaining the queries is feasible, labeling each document as relevant or not is often very time intensive—which is why there are relatively so few large closed IR datasets. We've found that for complex, knowledge intensive queries, evaluating whether a document is correct can take anywhere from 10 seconds to 30 minutes per document—generating labels on the scale of MS Marco would take thousands or millions of person-hours.
Our Approach: Open Evaluations
We've argued in the prior section that closed evals, while scientifically principled, can't capture how well a search provider would perform in a real world setting.
We were originally motivated by the problem of scale and false negatives—we wanted to evaluate over indexes in the billions, where determining the complete set of positive documents would be practically infeasible.
Now, for some queries, you could imagine setting a single labeled positive document: "wikipedia page of the runner up in the 1960 democratic primary". Here there's one good document: Lyndon B Johnson's Wikipedia page. We can be confident that any another document is worse. However, for most queries, there isn't a sole objective answer—consider "best blog posts about evals"—this is an ever-changing set, where the only way to determine if a result is better than other ones is by looking at each result.
Instead, at Exa we've moved to what we call "open evals"—open because unlike closed evals, they're not designed with a fixed index. An open eval simply is a list of queries, which can be run over any index. Defined this way, it feels almost trivial to give this a name, but it has important consequences.
As we noted above, for a massive, non-fixed index, we can't specify the labeled positive documents. Instead, we take advantage of LLM labelers. An open eval is always graded by an LLM. Thus, the flow of an LLM evaluation is simple:
- Define queries
- Choose a search provider
- Search the queries
- For each query, document result, prompt an LLM to give a scalar relevance grade
- Report the aggregate relevance score
This has some downsides, as we'll note, but has a number of important advantages:
- We can now evaluate on black box search providers, without needing to specify the index
- It's efficient to run on massive indexes
- Much less labor intensive to create evals—you only have to specify the queries
- Works naturally not just for grading raw search results, but also LLM outputs from those results
However, this has tradeoffs. This is the same flow as grading LLM outputs—at a high level, it's just a prompt+black box output → LLM grade—and shares all the challenges of LLM evaluation:
- Expensive to run: We now need to pass up to 1000s of tokens per document to an LLM, with multiple documents per query
- More grading variance: This introduces non-determinism from the LLM, as well as non-determinism from hitting production systems. Both can be mitigated, but fundamentally is less reproducible
- Heavily dependent on the grading prompt: This essentially reduces down to how well the LLM grading prompt matches human (or agent) preferences. There's lots of work involved, but thanks to the capacity of LLMs luckily we found it's very much an 80/20 scenario—most reasonable prompts work, for most grading tasks
- Verification gap: Even with a good prompt, there's a bit of a mismatch here. Fundamentally, the point of retrieval is to provide information that the LLM doesn't already know—if an LLM knew it, we wouldn't need RAG at all. It's a little odd then, to trust an LLM to grade results that it doesn't know the right answer to. This is an important point, and we'll dwell on it in the next section
How We Address the Verification Gap
How did we build a system where we can trust LLM grades of things it doesn't already know the answer to? There are a few important points.
Most of Search is... Dumb
First, most existing search systems spend orders of magnitude less compute per document than LLMs do. This is something we're actively rectifying at Exa. But out of necessity, retrieving over billions of documents in a latency sensitive way means they can't afford much. This typically means retrieving the initial set of documents through embeddings or term matching, and then reranking with a small (<1B params) reranker. Because of this, we'd expect in general to trust the ranking of raw search results less than that of a much larger LLM with both more knowledge and more tokens to spend reasoning about the document.
We can see this ourselves—Google a query like "research papers less than 8 pages citing LeCun"—the results fail in obvious ways that an LLM could detect.
Remember, our goal is not necessarily to get the platonic quality of any given document—a somewhat undefined concept. We just need a grader such that over large n, the average grade of a better retrieval system is better than that of a worse one—and the LLM's capacity advantage over retrieval systems gets us closer to that.
Most Queries Are Contextual
Second, some queries are explicitly or implicitly dependent on external facts not present in the page, like "university homepage of the Turing Award winner in 2004". However, a large fraction of documents either explicitly contain much of the information to determine whether it satisfies the query, or contain enough proxy signals to correlate which is the better document. This still fails sometimes, and often in correlated ways—one search engine might overindex on high quality pages, at the cost of relevance/correctness—and we want to be able to determine that!
In particular, we bias our query sets towards queries that can be graded contextually.
Expected Answers
For queries with niche factual knowledge, or specific criteria—we can just pass the expectations to the LLM grader—simply specify the criteria a good document should satisfy, or the facts an answer should contain, and prompt the LLM grader to consider that.
One might object—providing the expected answer sounds a lot like the closed evals we were trying to avoid. But the point of removing explicit labels from the closed evals was because it was impractical to label each document in the corpus, and because providing an explicit correct document often leads to false negatives when there exist other better documents.
By providing general facts or criteria a document should satisfy, we can allow the LLM to match the document for semantic criteria, not brittle exact matches of particular documents. This provides other benefits too—we can now get fine grained breakdowns of which searchers systematically fail certain criteria, if shared between documents.
In conclusion, there's no silver bullet, but with a combination of powerful LLMs, good prompts, careful querying, and labeling expected answers, we've found we can get pretty far.
As search engines improve—and as we push the bounds of Exa, where we design our search from the ground up to take advantage of LLM capabilities—different approaches will have to reign. We've found for many queries that grading Exa search results is often beyond the capacity of (bandwidth limited) humans. In later posts, we'll talk more about this -- Super Alignment (rip) for search if you will.
Our Grading Methodology
Open evals require delegating the actual grading to LLMs. While LLMs are intelligent (in spiky ways), getting this right requires careful calibration.
Aggregation Method
We've specified our queries, ran them through different search engines, and now have a list of (query, [documents], search_engine). What should the LLM see, and how should we aggregate it? We considered three main approaches:
- Pointwise: Flatten the list—make an LLM output a numerical grade for each
(query, document)pair, then group by query and average the grades - Pairwise: For each query, generate all possible pairs of searchers. Pass the results for each searcher into one LLM call, asking the LLM to select the best result set. Use the pairwise win data to compute the ELO of each searcher
- Listwise: For each query, take the top n results from each searcher, randomly interleave them, and ask an LLM to reorder them by quality. Average the position metrics for each searcher
Each method has its merits. Pointwise is simplest to run and allows more controllability over aggregation. Pairwise is more theoretically sound—it's unclear what the pointwise numerical grading scale even means. What delineates a document between 0.7 and 0.75?
Similarly, it's not immediately clear that LLMs can output transitive consistent scores—if it gives one document a 0.6 in one call, will it definitely give a better one an 0.7? That would require it to have an understanding of the distribution of result quality. By doing relative comparisons, pairwise solves this.
Listwise shares the same relative grading benefits as pairwise, with O(n) LLM calls, at the cost of much larger context—it's a challenging task that LLMs can't do perfectly. In addition, putting all the documents in context allows the LLM to use information from other documents to help grade each other, and evaluate diversity as well as pointwise quality.
In short, in theory we've concluded that pairwise probably gives the most consistent scores, while pointwise is the easiest to run and interpret.
However, we've found despite its theoretical limitations, the results of pointwise evals tend to really closely track the results of pairwise evals. In most cases we default to pointwise, but occasionally look at pairwise.
Aggregating Pointwise Scores
Once we have individual scores for each result, we need to aggregate them into a score per query. We've experimented with several approaches:
- Mean: Simple average of all result scores
- Median: Middle score, robust to outliers
- Rank-weighted mean: Sum of score/rank², giving more weight to top results
- NDCG: Normalized Discounted Cumulative Gain, a standard IR metric that heavily weights top positions
Each metric emphasizes different aspects of search quality. Mean treats all results equally, median provides robustness against particularly bad results, rank-weighted metrics emphasize top result quality, and NDCG is the most aggressive in prioritizing the first few results.
Interestingly, we've found that over large numbers of queries, the relative ordering of search engines remains fairly constant across these aggregation methods. This consistency suggests our performance differences are robust and not artifacts of any particular metric choice. We report mean scores for simplicity and interpretability, but have confidence this reflects genuine quality differences.
Number of Results
We evaluate the top 5 results per query for computational efficiency. Our testing showed high agreement between evaluating 5, 10, and 20 results—the relative performance between search engines remains consistent regardless of depth.
Grading Prompt
Determining the prompt for grading is where we spent much of our time—all the clever aggregation, visualizations, or queries can't overcome a grader that doesn't track with what we care about.
The only way to pin this down was by careful iteration. We started with the standard ingredients for a good prompt: clear instructions with core principles, examples, chain of thought or reasoning, and then saw how it did. We built a tool to make it easy to create human preferences on search results in order to validate and iterate on our prompt, and found that after a lot of iteration, our refined prompt matched human preferences 97% of the time on easy examples, and 83% on hard/ambiguous ones—close to how much different humans agreed with each other.
The full prompt we use for internal use is:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
You are a helpful assistant that grades the relevance of search results for given queries.
Your task is to assign a relevance score between 0.0 and 1.0 to each result, where:
1.0: Perfect match - The result provides exactly what was asked for with high quality and authority
0.8-0.9: Excellent match - Very relevant and high quality, with minor imperfections
0.6-0.7: Good match - Clearly relevant but may be missing some aspects or quality issues
0.4-0.5: Fair match - Partially relevant but significant gaps or quality concerns
0.2-0.3: Poor match - Only tangentially related or major quality issues
0.0-0.1: Irrelevant - Does not meaningfully address the query
Key scoring principles:
- We want exact matches to the user's query - if they ask for a specific entity or type of information, that's what we need
- Lists or general articles about a topic are not good matches when the user wants a specific entity
- Consider both relevance to the query AND the quality/authority of the source
- Use decimal points for fine-grained differentiation (e.g. 0.85 vs 0.82)
- Be consistent in your scoring across different queries
KEEP in mind -- you are seeing a (sometimes truncated) snippet of the result, and results may not necessarily have all the information necessary to determine
whether they match the query. For example, if the query is "companies founded after 2020", a company homepage is a good result, even if the homepage doesn't mention the year.
Use your judgement and knowledge of the query and the result to make the best determination.
Above all else, your job is to use your judgement to determine what would be a good search result for a user interested in direct links to their, sometimes complex queries. USE YOUR JUDGEMENT.
# Criteria Descriptions:
#
# 1. query_relevance: This measures how well the search result matches the user's query. A high score means the result directly and fully answers the query, while a low score means the result is only tangentially related or irrelevant.
#
# 2. result_quality: This assesses the authority, accuracy, and trustworthiness of the result. High-quality results come from reputable sources, are well-written, and are not spammy or misleading.
#
# 3. content_issues: This is a boolean indicating whether there are problems with the content, such as truncation, missing information, or improper parsing. If the result is incomplete or garbled, set this to True.
#
# 4. confidence: This reflects how certain you are about your grading. If the result snippet is clear and directly answers the query, confidence should be high. If you need external information to validate whether the result is a good match for the query, your confidence should be lower.
#
# 5. score: This is your overall assessment of the result, on a scale from 0.0 (irrelevant) to 1.0 (perfect match), taking into account both relevance and quality.
#
# Instructions:
#
# For each search result, carefully read the query and the result. Assign a value for each criterion as follows:
# - Provide a brief explanation of your reasoning.
# - Assign a query_relevance score between 0.0 and 1.0.
# - Assign a result_quality score between 0.0 and 1.0.
# - Indicate if there are any content_issues (True/False).
# - Assign a confidence score between 0.0 and 1.0.
# - Assign an overall score between 0.0 and 1.0.
#
# Be consistent and use decimal points for fine-grained differentiation. If you are unsure due to missing or unclear information, lower your confidence and make a best guess as to the score.However, in order to avoid unintentionally biasing results, we've run these evals with a much more minimal prompt, which we’ve found to have high correlation with the gold standard prompt above:
1
2
3
4
5
6
7
8
9
10
You are a helpful assistant that grades the relevance of search results for given queries.
Your task is to assign a relevance score between 0.0 and 1.0 to each result, based on how good a result is for the query.
For each search result, carefully read the query and the result. Assign a value for each criterion as follows:
- Provide a brief explanation of your reasoning.
- Assign a query_relevance score between 0.0 and 1.0.
- Assign a result_quality score between 0.0 and 1.0.
- Indicate if there are any content_issues (True/False).
- Assign a confidence score between 0.0 and 1.0.
- Assign an overall score between 0.0 and 1.0.Model Selection
We use GPT-4.1 for grading. While absolute scores vary between models, we found high ranking agreement between GPT-4o, GPT-4o-mini, GPT-4.1, and Gemini Flash 2.5. This consistency indicates rankings reflect quality differences rather than model-specific biases.
While most other search engines return snippets as content, Exa returns lots of page contents per result. For RAG applications, snippets often miss critical context, making them less useful even if they seem relevant. However, we evaluate what users actually receive from each API to ensure fair comparison.
We've also run experiments normalizing content—using Exa's content for all search engines' results. While this increases other engines' scores, Exa's advantage persists, showing our edge comes from better retrieval, not just better content extraction.
An interesting finding: for many queries, LLM grading based solely on URL and title correlates highly with full-text grading. However, this correlation breaks down for subtle, challenging queries—exactly where search quality matters most.
Handling Failures
Production search systems occasionally fail. We retry failed queries up to 5 times with exponential backoff. Queries where any engine fails all retries are excluded from results.
API Configuration
Apart from result count and content settings, we use default API parameters for all search engines. This reflects how most users interact with these services and avoids cherry-picking configurations that might favor particular approaches.
Statistical Rigor
Eval scores are inherently a random variable. We find it really useful to report confidence intervals around any aggregation, in order to get intuition for the effect sizes of the difference in score. See this paper for an accessible overview. Even confidence intervals, with clustered errors, doesn't perfectly capture the correlated nature of errors, but is a good start.
Importance of Manual Review
If you've gotten this far, you've now read thousands of words on how we automate evals. This is indispensable if we want to make principled decisions and improvements to search systems. Getting a comprehensive picture of the performance of even a single search system requires aggregating dozens if not hundreds of queries, and making fine grained distinctions in average performance. It's not feasible to ask humans to do this, especially repeatedly.
That said, there is still no substitute for manually running a few queries ourselves. Evals, especially LLM graded, provide a narrow and sometimes biased window into the performance of retrieval systems. I can't count the number of times manually looking at a few query results has given us insight that the evals missed.
This can also be helped with automation—at the very least, in our eval interface, we built an easy way to run queries through different search engines and display the results side by side.
Why This Approach Matters
Our evaluation philosophy directly impacts how we build Exa:
- Real-world optimization: By evaluating on actual query distributions over full web-scale indexes, we ensure Exa performs well on the searches that matter to users.
- Rapid iteration: Open evaluations let us rapidly test improvements without waiting for human labeling or being constrained by fixed corpora.
- Comprehensive measurement: By evaluating both result quality and downstream task performance, we ensure Exa works well both for direct search and as a tool for LLMs.
- Current relevance: Our evaluation approach naturally handles emerging topics and current events that fixed benchmarks miss.
Future Directions
We've released a simple subset of the evals we use to evaluate search quality. There are many more facets of search quality that we test internally, and many more ways we're actively working on testing frontier search, that matches or exceeds human (and LLM) capacity to judge. We're excited to keep sharing improved, scalable, and automated benchmarks/frameworks for judging search quality.


